如何使用DolphinDB处理Tushare金融数据
DolphinDB是新一代的时序数据库,不仅可以作为分布式数据仓库或者内存数据库来使用,而且自带丰富的计算工具,可以作为研究工具或研究平台来使用,非常适用于量化金融、物联网等领域的海量数据分析。量化金融领域的不少问题,如交易信号研究、策略回测、交易成本分析、股票相关性研究、市场风险控制等,都可以用DolphinDB来解决。
本教程将介绍如何把Tushare的沪深股票2008年到2017年的日线行情数据和每日指标数据导入到 DolphinDB database,并使用DolphinDB进行金融分析。Tushare是金融大数据开放社区,拥有丰富的金融数据,如股票、基金、期货、数字货币等行情数据,为量化从业人员和金融相关研究人员免费提供金融数据。
1. 数据概况
Tushare提供的沪深股票日线行情数据包含以下字段:
名称 描述 ts_code 股票代码 trade_date 交易日期 open 开盘价 high 最高价 low 最低价 close 收盘价 pre_close 昨收价 change 涨跌额 pct_change 涨跌幅 vol 成交量(手) amount 成交额(千元)
每日指标数据包含以下字段:
名称 描述 ts_code 股票代码 trade_date 交易日期 close 收盘价 turnover_rate 换手率 turnover_rate_f 换手率(自由流通股) volume_ratio 量比 pe 市盈率(总市值/净利润) pe_ttm 市盈率(TTM) pb 市净率(总市值/净资产) ps 市销率 ps_ttm 市销率(TTM) dv_ratio 股息率 dv_ttm 股息率(TTM) total_share 总股本(万) float_share 流通股本(万) free_share 自由流通股本(万) total_mv 总市值(万元) cric_mv 流通市值(万元)
2. 创建DolphinDB数据库
2.1 安装DolphinDB
从官网下载DolphinDB安装包和DolphinDB GUI.
DolphinDB单节点部署请参考单节点部署。
DolphinDB单服务器集群部署请参考单服务器集群部署。
DolphinDB多物理服务器部署请参考多服务器集群部署。
2.2 创建数据库
我们可以使用database函数创建分区数据库。
语法:database(directory, [partitionType], [partitionScheme], [locations])
参数
directory:数据库保存的目录。DolphinDB有三种类型的数据库,分别是内存数据库、磁盘上的数据库和分布式文件系统上的数据库。创建内存数据库,directory为空;创建本地数据库,directory应该是本地文件系统目录;创建分布式文件系统上的数据库,directory应该以“dfs://”开头。本教程使用分布式文件系统上的数据库。
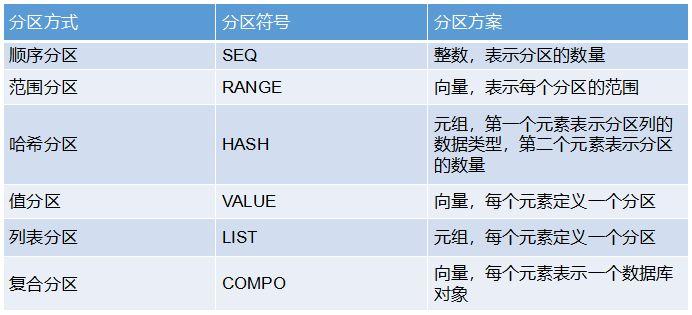
partitionType:分区方式,有6种方式: 顺序分区(SEQ),范围分区(RANGE),哈希分区(HASH),值分区(VALUE),列表分区(LIST),复合分区(COMPO)。
partitionScheme:分区方案。各种分区方式对应的分区方案如下:
导入数据前,要做好数据的分区规划,主要考虑两个因素:分区字段和分区粒度。
在日常的查询分析中,按照日期查询的频率最高,所以分区字段为日期trade_date。如果一天一个分区,每个分区的数据量过少,只有3000多条数据,不到1兆大小,而且分区数量非常多。分布式系统在执行查询时,会把查询语句分成多个子任务发送到不同的分区。这样的分区方式会导致子任务数量非常多,而每个任务执行的时间极短,系统在管理任务上耗费的时间反而大于任务本身的执行时间,明显这样的分区方式是不合理。这种情况下,我们按日期范围进行分区,每年的1月1日到次年的1月1日为一个分区,这样既能提升查询的效率,也不会造成分区粒度过小。
现有数据的时间跨度是2008-2017年,但是为了给未来的数据留出足够的空间,我们把时间范围设置为2008-2030年。执行以下代码:
yearRange=date(2008.01M + 12*0..22)
由于日线行情和每日指标数据的分区方案相同,因此把它们存放在同一个数据库dfs://tushare的两个表中,hushen_daily_line用于存放日线行情数据,hushen_daily_indicator用于存放每日指标数据。如果需要使用内存数据库,创建数据库时把directory设为空;如果需要使用磁盘上的数据库,把directory设置为磁盘目录即可。创建数据库的代码如下:
login("admin","123456")
dbPath="dfs://tushare"
yearRange=date(2008.01M + 12*0..22)
if(existsDatabase(dbPath)){
dropDatabase(dbPath)
}
columns1=`ts_code`trade_date`open`high`low`close`pre_close`change`pct_change`vol`amount
type1=`SYMBOL`NANOTIMESTAMP`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE
db=database(dbPath,RANGE,yearRange)
hushen_daily_line=db.createPartitionedTable(table(100000000:0,columns1,type1),`hushen_daily_line,`trade_date)
columns2=`ts_code`trade_date`close`turnover_rate`turnover_rate_f`volume_ratio`pe`pe_ttm`pb`ps`ps_ttm`dv_ratio`dv_ttm`total_share`float_share`free_share`total_mv`circ_mv
type2=`SYMBOL`NANOTIMESTAMP`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE`DOUBLE
hushen_daily_indicator1=db.createPartitionedTable(table(100000000:0,columns2,type2),`hushen_daily_indicator,`trade_date)3. 使用Python API把数据导入到DolphinDB
Tushare提供了两种常用的数据调取方式:
- 通过Tushare Python包,返回的是python dataframe类型数据。
- 通过http协议直接获取,返回的是Json格式数据。
本教程使用了第一种方法调取沪深股票2008年到2017年10年的日线行情数据和每日指标数据。
3.1 下载安装Python3.X和Tushare
具体教程请参考Tushare官网。
3.2 安装DolphinDB的Python3 API
从官网下载Python3 API,把Python3 API的安装包解压至任意目录。在console中进入该目录,执行以下命令:
python setup.py install
使用以下命令更新Python API:
python setup.py install --force
3.3 数据导入
我们分别使用Tushare Python包的daily和daily_basic接口调取日线行情和每日指标数据,返回的是Python Dataframe类型数据。注意,需要注册Tushare账号才能获取token。接着,通过Python API,连接到IP为localhost,端口号为8941的DolphinDB数据节点(这里的数据节点IP与端口根据自己集群的情况进行修改),把Tushare返回的Dataframe数据分别追加到之前创建的DolphinDB DFS Table中。
注意pro = ts.pro_api("Your Token")部分需要填入您的token,对于示例代码用到的函数接口daily_basic以及daily根据Tushare官网的要求, 需要达到600积分才能使用,详情可以参考官网的权限说明。关于积分,具体请参阅 积分获取办法。
具体的Python代码如下:
import datetime import tushare as ts import pandas as pd import numpy as np import dolphindb as ddb pro = ts.pro_api("Your Token") # replace by your own token s = ddb.session() s.connect("localhost", 8848, "admin", "123456") t1 = s.loadTable(tableName="hushen_daily_line", dbPath="dfs://tushare") t2 = s.loadTable(tableName="hushen_daily_indicator", dbPath="dfs://tushare") def dateRange(beginDate, endDate): dates = [] dt = datetime.datetime.strptime(beginDate, "%Y%m%d") date = beginDate[:] while date <= endDate: dates.append(date) dt = dt + datetime.timedelta(1) date = dt.strftime("%Y%m%d") return dates for dates in dateRange('20080101', '20171231'): df = pro.daily(trade_date=dates) df['trade_date'] = pd.to_datetime(df['trade_date']) if len(df): t1.append(s.table(data=df)) print(t1.rows) for dates in dateRange('20080101', '20171231'): ds = pro.daily_basic(trade_date=dates) ds['trade_date'] = pd.to_datetime(ds['trade_date']) ds['volume_ratio'] = np.float64(ds['volume_ratio']) if len(ds): t2.append(s.table(data=ds)) print(t2.rows)
数据导入成功后,我们可以从DolphinDB GUI右下角的变量浏览器中看到两个表的分区情况:
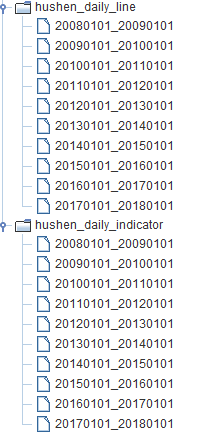
查看数据量:
select count(*) from hushen_daily_line 5,337,516 select count(*) from hushen_daily_indicator 5,337,517
至此,我们已经把沪深股票2008年-2017年的日线行情和每日指标数据全部导入到DolphinDB中。
4. 金融分析
DolphinDB将数据库、编程语言和分布式计算融合在一起,不仅可以用作数据仓库,还可以用作计算和分析工具。DolphinDB内置了许多经过优化的时间序列函数,特别适用于投资银行、对冲基金和交易所的定量查询和分析,可以用于构建基于历史数据的策略测试。下面介绍如何使用Tushare的数据进行金融分析。
4.1 计算每只股票滚动波动率
daily_line= loadTable("dfs://tushare","hushen_daily_line")
t=select ts_code,trade_date,mstd(pct_change/100,21) as mvol from daily_line context by ts_code
select * from t where trade_date=2008.11.14
------------output-------------
ts_code trade_date mvol
000001.SZ 2008.11.14T00:00:00.000000000 0.0486
000002.SZ 2008.11.14T00:00:00.000000000 0.0457
000004.SZ 2008.11.14T00:00:00.000000000 0.0307
000005.SZ 2008.11.14T00:00:00.000000000 0.0467
000006.SZ 2008.11.14T00:00:00.000000000 0.0431
000008.SZ 2008.11.14T00:00:00.000000000 0.0358
000009.SZ 2008.11.14T00:00:00.000000000 0.0511
000010.SZ 2008.11.14T00:00:00.000000000 0.0273
000012.SZ 2008.11.14T00:00:00.000000000 0.0529
000014.SZ 2008.11.14T00:00:00.000000000 0.0531
000016.SZ 2008.11.14T00:00:00.000000000 0.037
000018.SZ 2008.11.14T00:00:00.000000000 0.0353
...计算每只股票一个月的滚动波动率,仅需一行代码。DolphinDB自带金融基因,内置了大量与金融相关的函数,可以用简单的代码计算金融指标。
4.2 找到最相关的股票
使用沪深股票日线行情数据,计算股票的两两相关性。首先,生成股票回报矩阵:
retMatrix=exec pct_change/100 as ret from loadTable("dfs://tushare","hushen_daily_line") pivot by trade_date,ts_codeexec和pivot by是DolphinDB编程语言的特点之一。exec与select的用法相同,但是select语句生成的是表,exec语句生成的是向量。pivot by用于整理维度,与exec一起使用时会生成一个矩阵。
接着,生成股票相关性矩阵:
corrMatrix=cross(corr,retMatrix,retMatrix)
上面使用到的cross是DolphinDB中的高阶函数,它以函数和对象作为输入内容,把函数应用到每个对象上。模板函数在复杂的批量计算中非常有用。
然后,找到每只股票相关性最高的10只股票:
colName = strReplace(`c + string(corrMatrix.columnNames()), ".", "_") //注意此处修改是为了维护表列名的合法性 corrTb = table(corrMatrix.columnNames() as ts_code, corrMatrix).rename!(corrTb.columnNames()[1:], colName) mostCorrelated = select * from corrTb.unpivot(`ts_code, colName).rename!(`ts_code`corr_ts_code`corr) context by ts_code having rank(corr,false) between 1:10
查找与000001.SZ相关性最高的10只股票:
select * from mostCorrelated where ts_code="000001.SZ" order by corr desc ------------output------------- ts_code corr_ts_code corr 000001.SZ c601166_SH 0.859 000001.SZ c600000_SH 0.8406 000001.SZ c002920_SZ 0.8175 000001.SZ c600015_SH 0.8153 000001.SZ c600036_SH 0.8129 000001.SZ c600016_SH 0.8022 000001.SZ c002142_SZ 0.7956 000001.SZ c601169_SH 0.7882 000001.SZ c601009_SH 0.7778 000001.SZ c601328_SH 0.7736
上面两个示例都比较简单,下面我们进行复杂的计算。
4.3 构建World Quant Alpha #001和#98
WorldQuant LLC发表的论文101 Formulaic Alphas中给出了101个Alpha因子公式。很多个人和机构尝试用不同的语言来实现这101个Alpha因子。本文中,我们例举了较为简单的Alpha #001和较为复杂的Alpha #098两个因子的实现。
Alpha#001公式:rank(Ts_ArgMax(SignedPower((returns<0?stddev(returns,20):close), 2), 5))-0.5
Alpha #001的详细解读可以参考【史上最详细】WorldQuant Alpha 101因子系列#001研究。
Alpha#98公式:(rank(decay_linear(correlation(vwap, sum(adv5,26.4719), 4.58418), 7.18088))- rank(decay_linear(Ts_Rank(Ts_ArgMin(correlation(rank(open), rank(adv15), 20.8187), 8.62571), 6.95668) ,8.07206)))
这两个因子在计算时候既用到了cross sectional的信息,也用到了大量时间序列的计算。也即在计算某个股票某一天的因子时,既要用到该股票的历史数据,也要用到当天所有股票的信息,所以计算量很大。
构建这两个因子,需要包含以下字段:股票代码、日期、成交量、成交量的加权平均价格、开盘价和收盘价。其中,成交量的加权平均价格可以通过收盘价和成交量计算得出。因此,日线行情的数据可以用于构建这两个因子。
构建因子的代码如下:
def alpha1(stock){
t= select trade_date,ts_code,mimax(pow(iif(ratios(close) < 1.0, mstd(ratios(close) - 1, 20),close), 2.0), 5) as maxIndex from stock context by ts_code
return select trade_date,ts_code,rank(maxIndex) - 0.5 as A1 from t context by trade_date
}
def alpha98(stock){
t = select ts_code,trade_date, wavg(close,vol) as vwap, open, mavg(vol, 5) as adv5, mavg(vol,15) as adv15 from stock context by ts_code
update t set rank_open = rank(open), rank_adv15 = rank(adv15) context by trade_date
update t set decay7 = mavg(mcorr(vwap, msum(adv5, 26), 5), 1..7), decay8 = mavg(mrank(9 - mimin(mcorr(rank_open, rank_adv15, 21), 9), true, 7), 1..8) context by ts_code
return select ts_code,trade_date, rank(decay7)-rank(decay8) as A98 from t context by trade_date
}构建Alpha #001仅用了2行核心代码,Alpha #98仅用了4行核心代码,并且所有核心代码都是用SQL实现,可读性非常好。SQL中最关键的功能是context by子句实现的分组计算功能。context by是DolphinDB对标准SQL的扩展。与group by每个组产生一行记录不同,context by会输出跟输入相同行数的记录,所以我们可以方便的进行多个函数嵌套。cross sectional计算时,我们用trade_date分组。时间序列计算时,我们用ts_code分组。与传统的分析语言Matlab、SAS不同,DolphinDB脚本语言与分布式数据库和分布式计算紧密集成,表达能力强,高性能易扩展,能够满足快速开发和建模的需要。
查看结果:
select * from alpha1(daily_line) where trade_date=2017.07.06 ------------output------------- trade_date ts_code A1 2017.07.06T00:00:00.000000000 000001.SZ 247.5 2017.07.06T00:00:00.000000000 000002.SZ 1,099.5 2017.07.06T00:00:00.000000000 000004.SZ 247.5 2017.07.06T00:00:00.000000000 000005.SZ 247.5 2017.07.06T00:00:00.000000000 000006.SZ 1,099.5 2017.07.06T00:00:00.000000000 000008.SZ 1,969.5 2017.07.06T00:00:00.000000000 000009.SZ 1,099.5 2017.07.06T00:00:00.000000000 000010.SZ 1,099.5 ... select * from alpha98(daily_line) where trade_date=2017.07.19 ------------output------------- ts_code trade_date A98 000001.SZ 2017.07.19T00:00:00.000000000 1,400 000002.SZ 2017.07.19T00:00:00.000000000 (63) 000004.SZ 2017.07.19T00:00:00.000000000 (2,199) 000005.SZ 2017.07.19T00:00:00.000000000 (2,311) 000006.SZ 2017.07.19T00:00:00.000000000 282 000007.SZ 2017.07.19T00:00:00.000000000 798 000008.SZ 2017.07.19T00:00:00.000000000 2,070 000009.SZ 2017.07.19T00:00:00.000000000 (1,310) 000010.SZ 2017.07.19T00:00:00.000000000 812 ...
在本地服务器, 使用单线程计算,Alpha #001耗时仅0.6627秒,复杂的Alpha #98耗时仅1.806秒,性能极佳。
4.4 动量交易策略
动量策略是投资界最流行的策略之一。通俗地讲,动量策略就是“追涨杀跌”,买涨得厉害的,卖跌得厉害的。下面将介绍如何在DolphinDB中测试动量交易策略。
最常用的动量因素是过去一年扣除最近一个月的收益率。动量策略通常是一个月调整一次,并且持有期也是一个月。本教程中,每天调整1/21的投资组合,并持有新的投资组合21天。
要测试动量交易策略,需要包含以下字段的数据:股票代码、日期、每股价格(收盘价格)、流通市值、股票日收益和每日交易量。
显然,只有日线行情的数据是不够的,我们需要连接hushen_daily_line和hushen_daily_indicator两个表。
通过equal join,从两个表中选择需要的字段:
s=select ts_code,trade_date,close,change,pre_close,vol,amount,turnover_rate,total_share,float_share,free_share,total_mv,circ_mv from ej(daily_line,daily_indicator,`ts_code`trade_date)
(1)对数据进行清洗和过滤,为每只股票构建过去一年扣除最近一个月收益率的动量信号。
def loadPriceData(inData){
stocks = select ts_code, trade_date,vol, close,change/pre_close as ret, circ_mv from inData where weekday(trade_date) between 1:5, isValid(close), isValid(vol) order by ts_code, trade_date
stocks = select ts_code, trade_date,close,ret,circ_mv, vol, cumprod(1+ret) as cumretIndex from stocks context by ts_code
return select ts_code, trade_date, close, ret, vol ,circ_mv, move(cumretIndex,21)\move(cumretIndex,252)-1 as signal from stocks context by ts_code
}
priceData = loadPriceData(s)(2)生成投资组合
选择满足以下条件的流通股:动量信号无缺失、当天的交易量为正、市值超过1亿元以及每股价格超过5元。
def genTradables(indata){
return select trade_date, ts_code, circ_mv, vol, signal from indata where close>5, circ_mv>10000, vol>0, isValid(signal) order by trade_date
}
tradables = genTradables(priceData)根据每天的动量信号,产生10组流通股票。只保留两个最极端的群体(赢家和输家)。假设在21天内,每天总是多头1元和空头1元,所以我们每天在赢家组多头1/21,在输家组每天空头1/21。在每组中,我们可以使用等权重或值权重,来计算投资组合形成日期上每个股票的权重。
//WtScheme=1表示等权重;WtScheme=2表示值权重
def formPortfolio(startDate, endDate, tradables, holdingDays, groups, WtScheme){
ports = select date(trade_date) as trade_date, ts_code, circ_mv, rank(signal,,groups) as rank, count(ts_code) as symCount, 0.0 as wt from tradables where date(trade_date) between startDate:endDate context by trade_date having count(ts_code)>=100
if (WtScheme==1){
update ports set wt = -1.0\count(ts_code)\holdingDays where rank=0 context by trade_date
update ports set wt = 1.0\count(ts_code)\holdingDays where rank=groups-1 context by trade_date
}
else if (WtScheme==2){
update ports set wt = -circ_mv\sum(circ_mv)\holdingDays where rank=0 context by trade_date
update ports set wt = circ_mv\sum(circ_mv)\holdingDays where rank=groups-1 context by trade_date
}
return select ts_code, trade_date as tranche, wt from ports where wt != 0 order by ts_code, trade_date
}
startDate=2008.01.01
endDate=2018.01.01
holdingDays=21
groups=10
ports = formPortfolio(startDate, endDate, tradables, holdingDays, groups, 2)
dailyRtn = select date(trade_date) as trade_date, ts_code, ret as dailyRet from priceData where date(trade_date) between startDate:endDate(3)计算投资组合中每只股票接下来21天的利润或损失。在投资组合形成后的21天关停投资组合。
def calcStockPnL(ports, dailyRtn, holdingDays, endDate, lastDays){
ages = table(1..holdingDays as age)
dates = sort distinct ports.tranche
dictDateIndex = dict(dates, 1..dates.size())
dictIndexDate = dict(1..dates.size(), dates)
pos = select dictIndexDate[dictDateIndex[tranche]+age] as date, ts_code, tranche, age, take(0.0,size age) as ret, wt as expr, take(0.0,size age) as pnl from cj(ports,ages) where isValid(dictIndexDate[dictDateIndex[tranche]+age]), dictIndexDate[dictDateIndex[tranche]+age]<=min(lastDays[ts_code], endDate)
update pos set ret = dailyRet from ej(pos, dailyRtn,`date`ts_code,`trade_date`ts_code)
update pos set expr = expr*cumprod(1+ret) from pos context by ts_code, tranche
update pos set pnl = expr*ret/(1+ret)
return pos
}
lastDaysTable = select max(date(trade_date)) as date from priceData group by ts_code
lastDays = dict(lastDaysTable.ts_code, lastDaysTable.date)
stockPnL = calcStockPnL(ports, dailyRtn, holdingDays, endDate, lastDays)(4)计算投资组合的利润或损失,并绘制动量策略累计回报走势图。
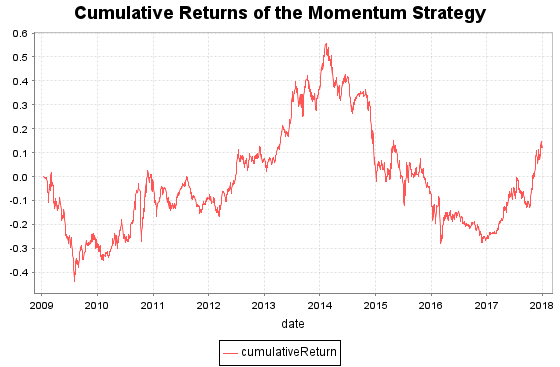
portPnL = select sum(pnl) as pnl from stockPnL group by date order by date plot(cumsum(portPnL.pnl) as cumulativeReturn,portPnL.date, "Cumulative Returns of the Momentum Strategy")
下面是沪深股票2008年到2017年的回测结果。回测时,每天产生一个新的tranche,持有21天。
如果使用Pandas来处理金融数据,对内存的要求较高,内存使用峰值一般是数据的3-4倍,随着数据的积累,pandas的内存占用问题会越来越明显。在性能上,pandas在多线程处理方面比较弱,不能充分利用多核CPU的计算能力,并且pandas不能根据业务字段对数据进行分区,也不支持列式存储,查询数据时必须全表扫描,效率不高。
5. 总结
作为数据库,DolphinDB支持单表PB级存储和灵活的分区方式;作为研究平台,DolphinDB不仅功能丰富,支持快速的数据清洗、高效的数据导入、交互式分析、库内分析,流计算框架和离线计算支持生产环境代码重用,而且性能极佳,即使面对庞大数据集,仍可以轻松实现秒级毫秒级的低延时交互分析。另外,DolphinDB对用户十分友好,提供了丰富的编程接口,如Python、C++、Java、C#、R等编程API和Excel的add-in插件、ODBC、JDBC插件,还提供了功能强大的集成开发工具,支持图形化数据显示,让实验结果更加直观易于理解。
欢迎访问官网下载DolphinDB试用版
我们的专栏DolphinDB和量化金融,包含更多量化金融方面的教程
联系邮箱:sales@dolphindb.com
- 发表于 2021-05-14 10:37
- 阅读 ( 8262 )
- 分类:DolphinDB和量化金融
