高频数据处理技巧:非等间隔的时间序列处理
高频时间序列的处理中,经常会用到滑动,偏移,聚合,转置,关联等操作。譬如说我想对一个某指标列用过去一个小时的数据的均值来做平滑处理,又或者想找到每一个时刻,该指标一个小时前的相应的指标值。如果序列中每个指标的间隔是相等的而且中间没有缺失数据,譬如说0.5s,3s,那么我们可以把时间窗口转化成固定记录条数的窗口,基本上常用的数据分析软件语言都可以完成滑动窗口函数功能。如果条件不能满足,就变成了比较复杂的非等间隔的时间序列处理问题。
假设有一组这样的数据:
time val ------ --- 12:31m 1 12:33m 2 12:34m 3 12:35m 4 12:37m 5 12:40m 6 12:41m 7 12:42m 8 12:43m 9 12:45m 10
我们在每一个时间点上,需要计算过去5分钟内val的均值。由于每条数据的时间间隔不相等,我们不能确定时间窗口的数据条数。因此,我们需要将数据逐条与时间窗口的边界对比,找到时间窗口中的数据,再计算avg(val)。
这一类问题,DolphinDB和kdb均提供了window join,可以方便地完成这一任务。DolphinDB的实现脚本如下:
t=table(12:31m 12:33m 12:34m 12:35m 12:37m 12:40m 12:41m 12:42m 12:43m 12:45m as time,1..10 as val) wj(t,t,-5:-1,<avg(val)>,`time) time val avg_val ------ --- ------- 12:31m 1 12:33m 2 1 12:34m 3 1.5 12:35m 4 2 12:37m 5 3 12:40m 6 4.5 12:41m 7 5.5 12:42m 8 6 12:43m 9 7 12:45m 10 7.5
window join需要提供左右表、时间窗口、聚合函数和连接列。左表用于指定发生计算的时间点,右表是原始数据。-5:-1是时间窗口,表示当前时刻的前5分钟。如果时间窗口的上下边界都为正数,如1:5,表示当前时刻的后5分钟。如果时间窗口的边界为0,如-5:0或0:5,表示当前时刻也包含在时间窗口内。如果时间窗口的上下边界是一正一负,如-5:5,表示过去5分钟到未来5分钟,当前时刻也包含在窗口中。
下面详细解释一下计算过程。以第一条数据为例,发生计算的时间点为12:31m,数据窗口为12:31m-5到12:31m-1,即12:26m到12:30m,上下边界都包含在内。系统会在t中寻找时间在数据窗口的数据,并对它们计算avg(val),如此类推。
上面的例子中,数据只包含一只股票,如果数据包含多只股票,要求每一时刻每只股票过去5分钟的avg(val),那要怎么操作呢?window join可以指定多个连接列,系统会先根据前面N - 1连接列做等值连接(equal join),在每一个细分的组中,再根据最后一个连接列做window join。请看下面的例子,假设原始数据如下:
time sym val ------ --- --- 12:31m A 1 12:31m B 2 12:33m A 3 12:33m B 4 12:34m B 5 12:35m A 6 12:35m B 7 12:36m A 8 12:28m A 9 12:39m B 10 12:40m A 11 12:40m B 12
现在要计算每一时刻,过去5分钟内每只股票代码的avg(val)。脚本如下:
t=table(12:31m 12:31m 12:33m 12:33m 12:34m 12:35m 12:35m 12:36m 12:28m 12:39m 12:40m 12:40m as time,`A`B`A`B`B`A`B`A`A`B`A`B as sym,1..12 as val) wj(t,t,-5:-1,<avg(val)>,`sym`time) time sym val avg_val ------ --- --- -------- 12:31m A 1 12:31m B 2 12:33m A 3 1 12:33m B 4 2 12:34m B 5 3 12:35m A 6 2 12:35m B 7 3.666667 12:36m A 8 3.333333 12:28m A 9 12:39m B 10 6 12:40m A 11 7.666667 12:40m B 12 8.5
以左表的第一条数据为例,sym=A,time=12:31m,因此数据窗口为12:26m到12:30m,系统会在右表中寻找在时间窗口中的数据,并且sym=A的数据来计算avg(val)。
DolphinDB的window join支持任意聚合函数,既支持内置的avg、beta、count、corr、covar、first、last、max、med、min、percentile、std、sum、sum2、var和wavg, 也可以支持用户自定义的聚合函数;聚合函数的参数可以是一个,也可以是多个;参数既可以是表中的某一列,也可以是一个计算字段。
和不同的聚合函数结合,可以满足很多业务场景的需要。试想这样一个场景,有两个表t1和t2,它们的内容如下:
t1=table(1 3 5 7 2 as id, 2012.06.12 2013.06.26 2014.06.14 2015.06.23 2016.06.19 as date) t2=table(1 2 6 7 8 as id,5 2 4 7 9 as val,2014.10.20 2015.02.05 2016.08.15 2017.12.23 2018.06.23 as date)
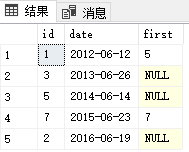
现在要找出t2中与t1的id对应,并且时间在t1时间之后的第一条记录。使用DolphinDB可以非常方便地实现:
wj(t1,t2,1:(365*100),<first(val)>,`id`date) id date first_val -- ---------- --------- 1 2012.06.12 5 3 2013.06.26 5 2014.06.14 7 2015.06.23 7 2 2016.06.19
这里我们设置的数据窗口是1:36500,即100年。这是为了防止t2中每条数据date2的间隔过大,数据没有落在数据窗口中的情况出现。在传统数据库中,如SQL Server,需要通过自定义函数来实现。代码如下:
create table t1(id int,date date) insert into t1 values(1,'2012-06-12') insert into t1 values(3,'2013-06-26') insert into t1 values(5,'2014-06-14') insert into t1 values(7,'2015-06-23') insert into t1 values(2,'2016-06-19') go create table t2(id int,val int,date date) insert into t2 values(1,5,'2014-10-20') insert into t2 values(2,2,'2015-02-05') insert into t2 values(6,4,'2016-08-15') insert into t2 values(7,7,'2017-12-23') insert into t2 values(8,9,'2018-06-23') go create function [dbo].[getRight] ( @curid int, @curdate date ) returns int as begin declare @reV int select top 1 @reV = val from t2 where id=@curid and date>=@curdate return @reV end go select id,date,dbo.getRight(id,date) as 'first' from t1
SQL Server的性能较差,DolphinDB大约比SQL Server快300倍。
pandas的rolling函数只能处理等时间间隔的数据,不能处理非等时间间隔的数据。DolphinDB和kdb+则都可解决。下面我们随机生成一个一千万行的表来测试DolphinDB和kdb+中window join的性能。测试使用的机器配置如下:
CPU:Intel(R) Core(TM) i7-7700 CPU @3.60GHz 3.60 GHz
内存:16GB
OS:Windows 10
DolphinDB脚本如下:
n=10000000 t=select * from table(rand(2012.06.12T12:00:00.000..2012.06.30T12:00:00.000,n) as time,rand(`A`B`C`D`E,n) as sym,rand(100.0,n) as x) order by time timer wj(t,t,-6:0,<avg(x)>,`sym`time)
kdb+脚本如下:
n:10000000 t:`sym`time xasc ([]time:2012.06.12T12:00 + (n ? 1000000);sym:n ? `A`B`C`D`E;x:n ? 100.0) update `p#sym from `t f:`sym`time w:-6 0+\:t.time \t wj1[w;f;t;(t;(avg;`x))]
DolphinDB耗时456毫秒,kdb+耗时 16,398毫秒。我们调整时间窗口的长度,测试DolphinDB和kdb+的表现如何。时间窗口为60毫秒,DolphinDB耗时455毫秒,kdb+耗时21,521毫秒;时间窗口为600毫秒,DolphinDB耗时500毫秒,kdb+耗时73,649毫秒。可以看到,DolphinDB window join的性能与窗口长度无关,而kdb+ wj1中的性能与窗口的长度有关,窗口越长,耗时越长。这是因为DolphinDB对内置的聚合函数avg做了优化,在window join中的计算速度与窗口无关。这些优化的聚合函数包括avg、beta、count、corr、covar、first、last、max、med、min、percentile、std、sum、sum2、var和wavg。
DolphinDB database 下载:www.dolphindb.cn
- 发表于 2021-05-18 10:58
- 阅读 ( 3765 )
- 分类:DolphinDB和量化金融
