DolphinDB作为工业物联网数据后台的7大优势
DolphinDB是完全自主研发的新一代的高性能分布式时序数据库,以一站式大数据方案、快速开发、性能优异、综合使用成本低著称。DolphinDB目前广泛应用于量化金融和工业物联网两大场景。
数据是工业物联网的血液。但是国内绝大部分的MES系统,以及所谓的智慧工厂,对生产过程中产生的海量的工艺数据,保存不会超过三个月,更不用说进一步对积累的数据研究利用了。数据的实时采集、计算和反控则对工业物联网背后的数据平台的实时计算能力提出了很高的要求。传统的关系型数据库,大部分开源的NoSQL,以及新一代的NewSQL离工业物联网数据平台的这两个苛求要求还有较远的距离。
时序数据库应运而生。DolphinDB作为工业物联网数据后台时具有以下7大天然优势。
1. 一站式数据解决方案
工业物联网不仅要采集机器产生的工艺数据,还要进行实时计算和预警,并把结果展示给操作员或直接反馈给机器。同时需要将这些原始的工艺数据保存到数据库,供在线或离线查询。积累大量历史数据后,又可以进行更为复杂的大数据挖掘。而这一切都可以在DolphinDB一个系统内完成。下图展示了 DolphinDB database 的数据处理流程。
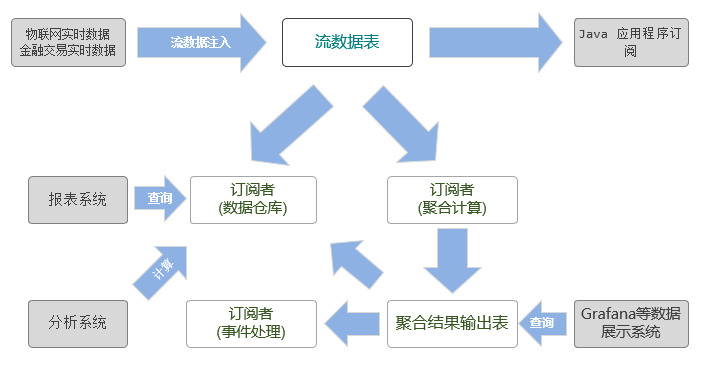
对于系统集成商或企业来说,在一套系统上进行开发和维护,比起在多套系统上集成、开发和维护,无论是开发成本,维护成本,还是硬件的采购成本都会低得多。
2. 轻量级跨平台部署
工业物联网平台通常非常复杂。既有廉价的工控机(低配的PC或嵌入式系统),也有服务器或服务器集群。既有边缘计算,也有本地平台部署和云端平台部署。涉及的操作系统既有Linux,也有Windows。市场上不少开源或商用的时序数据库,以及相关的大数据生态,部件众多复杂,体积庞大,对软硬件的要求较高。使用一套系统进行跨平台部署,难度很大。
DolphinDB是一个非常轻量级的系统,用GNU C++开发,系统大小仅20余兆,无任何依赖,可以部署在上述任何平台上。这大大节约了系统集成商的开发和维护成本。
3. 安全可控
工业物联网平台的数据及系统的安全可控对一个企业,乃至对国家都至关重要。DolphinDB是一个从零开始,完全自主研发的分布式时序数据库。从底层的分布式文件系统和存储引擎,到数据库和核心类库,到分布式计算引擎,到脚本语言,到各种编程语言的开发接口,甚至外围的开发集成环境GUI、集群管理工具都是百分百自主研发的,无任何外部依赖,安全可控。
DolphinDB除了支持x86和arm的指令体系外,也在适配MIPS指令体系,以支持龙芯等国产CPU。这样在工业物联网平台上,可以实现软硬件同时自主可控。
4. 海量历史数据存储和处理
工业物联网数据采集的维度高,频率高,设备数量多,数据量特别大,且都是高时间精度数据。目前制造业使用的MES系统大部分采用关系型数据库,往往只能保存极短时间内的工艺数据,无法保留全量高精度数据。数据库系统的限制,导致企业无法发挥历史数据的价值。
DolphinDB database 采用列式存储,支持数据压缩(压缩率在20%左右),最高支持纳秒精度的时间序列数据处理,单表支持百万级别分区。可以通过增加节点的方式水平扩展DolphinDB集群的存储能力和计算能力。DolphinDB集群支持多副本分布式存储和分布式事务,当一个副本的数据错误或丢失时,启用另一个副本恢复,保证数据的高可用和强一致。企业可以利用长年积累的历史数据进行深度数据挖掘和数据分析,如设备的预测性维护,工艺流程的改进,产品质量的提升,制造计划的优化等等。
简单的说,在同样的硬件设备上,关系型数据库(Oracle,SQL Server)可以支持亿级的时序数据,DolphinDB可以支持万亿级的时序数据。
5. 实时流计算
物联网实时采集的数据,可以交给DolphinDB的流计算引擎清洗、实时统计、即时入库,并通过可视化的方式实时展示。DolphinDB天然具备流表对偶性,发布一条消息相当于往流数据表中增加一条数据,可以直接使用SQL注入和查询分析流数据,极为方便。DolphinDB的流计算引擎是基于发布-订阅-消费的模式。通过流数据表发布数据,其他数据节点或第三方应用通过DolphinDB脚本或 API来订阅消费流数据,把计算结果实时反馈给机器或操作员。流计算教程可以参考DolphinDB流数据教程和DolphinDB流数据聚合引擎教程。
6. 丰富的计算功能
DolphinDB的计算功能可以说是市场上的时序数据库中最丰富的。DolphinDB内置了脚本语言,可直接在数据库中进行复杂的计算和交互分析,避免了数据迁移。大部分计算功能和函数都经过优化,性能远远超过其他数据库中的相同功能。下面列举了DolphinDB中常用的计算功能。
6.1 范围查询
DolphinDB使用数据对(pair)的形式表示范围。例如,查询某个表某个时间范围内的数据:
select * from table where date between beginDate:endDate
6.2 多维查询
DolphinDB可以针对不同列进行聚合,实现高维或低维的范围查询功能。例如,对field1,field2 列进行过滤并分组聚合:
select sum(prc) from table where field1 in (1..100) and field2 = ‘A’ group by field1, field2
6.3 抽样查询
DolphinDB提供了以分区为单位的抽样查询机制,可以按照指定的比例或者数量对分区进行抽样,只需要在where后调用sample函数。例如,按设备ID进行范围分区,抽取10%分区中的数据和10个分区中的数据
//抽样10%分区 select * from trades where sample(equipmentId, 0.1) //抽样10个分区 select * from trades where sample(equipmentId, 10)
6.4 精度查询
DolphinDB的时间精度达到纳秒,支持海量高精度历史数据存储,也支持把高精度大数据集聚合转换成低精度小数据集存储。同时,DolphinDB支持多种时间精度分组抽样。例如,选择某两个日期之间的数据,按分钟进行分组计算。
select avg(tint) from t1 where date(timestamp) between 2018.01.01:2018.10.11 group by minute(timestamp)
DolphinDB也支持自定义精度分组。例如,每5秒一个分组:
select avg(tint) from t1 where date(timestamp) between 2018.01.01:2018.10.11 group by bar(timestamp,5000)
6.5 插值查询
在工业领域经常会发生采集的数据缺失。DolphinDB在查询计算时提供了4种插值方式补全数据,向前/向后取非空值填充(bfill/ffill),线性填充(lfill)和指定值填充(nullFill)。用户也可以通过脚本或C++插件扩充新的插值函数。
6.6 聚合查询
DolphinDB的函数库非常丰富,支持以下聚合函数:atImax, atImin, avg, beta, contextCount, contextSum, contextSum2, count, corr, covar, derivative, difference, first, imax, last, lastNot, max, maxPositiveStreak, mean, med, min, mode, percentile, rank, stat, std,sum, sum2,var, wavg, wsum, zscore。
6.7 面板数据分组查询
处理面板数据时,有时候希望为每个分组的每一行数据生成一个值。DolphinDB提供了context by和滑动统计函数。
DolphinDB支持以下滑动统计函数:deltas, mavg, mbeta, mcorr, mcount, mcovar, mimax, mimin, mmax, mmed, mmin, mpercentile, mrank, mstd, msum, mvar, ratios。
例如,计算每台设备过去10个采集点的移动平均温度:
select equipmentId, mavg(temperature,10) as mavg_temperature context by equipmentId
DolphinDB对部分滑动统计函数进行了优化,每次计算时,充分利用上一个窗口的计算结果,最大程度地降低了重复计算。
6.8 对比查询
DolphinDB的pivot by可用于数据透视,特别是同一时间不同列的指标对比。例如,想要对比同一时间段不同设备的平均温度,可以使用以下代码:
equipmentId = `A`B`B`B`C`C`A`A`A$symbol; temperature= 49.6 29.46 29.52 30.02 174.97 175.23 50.76 50.32 51.29; timestamp = [09:34:07,09:35:42,09:36:51,09:36:59,09:35:47,09:36:26,09:34:16,09:35:26,09:36:12]; t = table(timestamp, equipmentId, temperature) select avg(temperature) from t pivot by timestamp.minute() as minute, equipmentId
返回的结果为:
minute A B C 09:34m 50.18 09:35m 50.32 29.46 174.97 09:36m 51.29 29.77 175.23
6.9 关联查询
DolphinDB支持的关联查询种类非常多,包括等值连接、完全连接、交叉连接、左连接、asof join和窗口连接。其中asof join和窗口连接(window join)是专门为时间序列数据设计的连接方式,能够满足更多场景的需求。
当两个表中的时间字段不完全对应时,可以使用asof join,如果左表中的时间为t,它会自动选择右表中不超过t的最近时间。窗口连接是asof join的扩展,如果窗口为w1:w2,它会在右表中选择(t+w1)到(t+w2)之间的数据,并对这些数据使用聚合函数。例如:
select equipmentId,t1.temperature,t2.humidity from aj(t1,t2,`timestamp) select * from wj(t1,t2,-5:0,<avg(temperature)>,`equipmentId`timestamp)
6.10 机器学习和分布式计算
DolphinDB提供了map-reduce,iterative map-reduce等分布式计算框架。用户只需要指定数据源、map函数、reduce函数和final函数,无需编译、部署,可以直接在线使用。为方便用户,DolphinDB内置了常用的拟合和分类算法,可在本地数据源和分布式数据源上使用,这些算法包括线性回归、广义线性模型(GLM)、随机森林(Random Forest)、逻辑回归等。后续将会推出更多机器学习算法。
除了已有的功能外,DolphinDB提供了几种途径扩展系统功能。DolphinDB内置强大的类SQL和Python的脚本语言。用户可以用脚本语言自定义函数来扩展系统功能。DolphinDB支持使用C++开发插件来扩展系统功能。除此以外,DolphinDB提供了C++、C#、Java、Python、R、JS、Excel等语言和系统的API,方便与其它系统集成。
7. 综合使用成本低
工业企业的利润率不高,如果数据平台成本(软硬件的采购成本,系统集成费用,维护费用,应用开发成本等)过高,会严重限制工业物联网的发展。DolphinDB一站式的解决方案、跨平台部署能力、强大的实时数据和海量历史数据处理能力、丰富的计算功能及扩展能力极大的降低了系统的综合拥有成本。
欢迎访问官网下载 DolphinDB database
咨询邮箱:info@dolphindb.com
- 发表于 2021-05-20 10:56
- 阅读 ( 3841 )
- 分类:DolphinDB和物联网
