时序数据库DolphinDB和TimescaleDB 性能对比测试报告
一、概述
DolphinDB
DolphinDB 是以 C++ 编写的一款分析型的高性能分布式时序数据库,使用高吞吐低延迟的列式内存引擎,集成了功能强大的编程语言和高容量高速度的流数据分析系统,可在数据库中进行复杂的编程和运算,显著减少数据迁移所耗费的时间。
DolphinDB 通过内存引擎、数据本地化、细粒度数据分区和并行计算实现高速的分布式计算,内置流水线、 Map Reduce 和迭代计算等多种计算框架,使用内嵌的分布式文件系统自动管理分区数据及其副本,为分布式计算提供负载均衡和容错能力。
DolphinDB 支持类标准 SQL 的语法,提供类似于 Python 的脚本语言对数据进行操作,也提供其它常用编程语言的 API,在金融领域中的历史数据分析建模与实时流数据处理,以及物联网领域中的海量传感器数据处理与实时分析等场景中表现出色。
TimescaleDB
TimescaleDB 是目前市面上唯一的开源且完全支持 SQL 的时序数据库。它在 PostgreSQL 数据库的基础上进行开发,本质上是一个 PostgreSQL 的插件。
TimescaleDB 完全支持 SQL 且拥有 PostgreSQL 的丰富生态、并针对时间序列数据的快速插入和复杂查询进行了优化,支持自动分片,支持时间空间维度自动分区,支持多个 SERVER、多个 CHUNK 的并行查询,内部写优化(批量提交、内存索引、事务支持、数据倒灌)。
然而,目前 TimescaleDB 仍不支持水平扩展(集群),即不能动态增加新的数据结点以写入数据(Write clustering for multi-node Timescale deployments is under active development. https://github.com/timescale/timescaledb/issues/9),只支持通过 PostgreSQL 的流复制(streaming replication)实现的只读集群(read-only clustering)。
在本报告中,我们对 TimescaleDB 和 DolphinDB,在时间序列数据集上进行了性能对比测试。测试涵盖了CSV数据文件的导入导出、磁盘空间占用、查询性能等三方面。在我们进行的所有测试中,DolphinDB 均表现得更出色,主要结论如下:
- 数据导入方面,小数据集情况下 DolphinDB 的导入性能是 TimescaleDB 的10多倍,大数据集的情况下导入性能是其100多倍,而且在导入过程中可以观察到随着导入时间的增加,TimescaleDB 的导入速率不断下降,而 DolphinDB 保持稳定。
- 数据导出方面,DolphinDB 的性能是 TimescaleDB 的 3 倍 左右。
- 磁盘空间占用方面,小数据集下 DolphinDB 占用的空间仅仅是 TimescaleDB 的 1/6 ,大数据集下占用空间仅仅是 TimescaleDB 的 1/17。
- 查询性能方面,DolphinDB 在4个测试样例中性能超过 TimescaleDB 50多倍 ;在15个测试样例中性能为 TimescaleDB 10 ~ 50 倍 ; 在10个测试样例中性能是 TimescaleDB 的数倍;仅有2个测试样例性能低于TimescaleDB。
二、测试环境
TimescaleDB 目前仍未支持能够写入数据的集群,因此我们使用单机进行测试。单机的配置如下。
主机:DELL OptiPlex 7060
CPU :Intel Core i7-8700(6 核 12 线程 3.20 GHz)
内存:32 GB (8GB × 4, 2666 MHz)
硬盘:2T HDD (222 MB/s 读取;210 MB/s 写入)
OS:Ubuntu 16.04 LTS
DolphinDB 的测试版本为 Linux v0.89 (2019.01.31),最大内存设置为28GB。测试时使用的 PostgreSQL 版本为 Ubuntu 10.6-1 on x86_64, TimescaleDB 插件的版本为 v1.1.1。根据 TimescaleDB 官方指南推荐的性能调优方法,结合测试机器的实际硬件配置,我们在 https://pgtune.leopard.in.ua/ 网站上生成了配置文件,同时参考了 https://wiki.postgresql.org/wiki/Tuning_Your_PostgreSQL_Server 这一官方配置指南作了优化,主要将 shared_buffers 和 effective_cache_size 设置为 16GB,并根据12线程 CPU 设置了 parallel workers,由于仅使用一块机械硬盘,我们将 effective_io_concurrency 设置为 1,具体修改的配置详见附录中 postgresql_test.conf 文件。
三、数据集
本报告测试了小数据量级(4.2 GB) 和 大数据量级(270 GB) 下 DolphinDB 和 TimescaleDB 的表现情况:
在小数据量级的测试中我们预先将硬盘中的分区数据表全部加载到内存中,即在 DolphinDB 中使用 loadTable(memoryMode=true),在 PostgresQL 中使用 pg_prewarm 插件将其加载至 shared_buffers。
在大数据量级的测试中我们不预先加载硬盘分区表,查询测试的时间包含磁盘 I/O 的时间,为保证测试公平,每次启动程序测试前均通过 Linux 系统命令 sync; echo 1,2,3 | tee /proc/sys/vm/drop_caches 分别清除系统的页面缓存、目录项缓存和硬盘缓存。
以下是两个数据集的表结构和分区方法:
4.2 GB 设备传感器记录小数据集(CSV 格式,3 千万条)
我们从 TimescaleDB 官方给出的样例数据集中选择了 devices_big 作为小数据集来测试,数据集包含 3000 个设备在 10000 个时间间隔(2016.11.15 - 2016.11.19)上的 传感器时间, 设备 ID, 电池, 内存, CPU 等时序统计信息。
来源:https://docs.timescale.com/v1.1/tutorials/other-sample-datasets
下载地址:https://timescaledata.blob.core.windows.net/datasets/devices_big.tar.gz
数据集共 3千万 条数据(4.2 GB CSV),压缩包内包含一张设备信息表和一张设备传感器信息记录表,表结构以及分区方式如下:
device_info 表
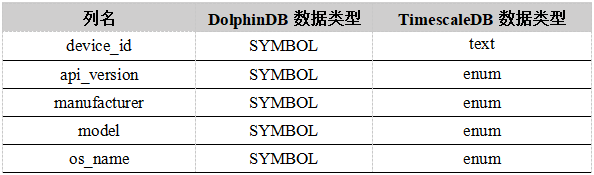
readings 表
数据集中device_id这一字段有 3000 个不同的值,这些值在 readings 表的记录中反复出现,用 text 类型不仅占用大量空间而且查询效率较低,但是在 TimescaleDB 中我们难以对这一字段采用 enum 类型,而 DolphinDB 的 Symbol 类型简单高效地解决了存储空间和查询效率这两大问题。
同样,对于bssid和ssid这两个字段表示设备连接的 WiFi 信息,在实际中因为数据的不确定性,虽然有大量的重复值,但并不适合使用 enum 类型。
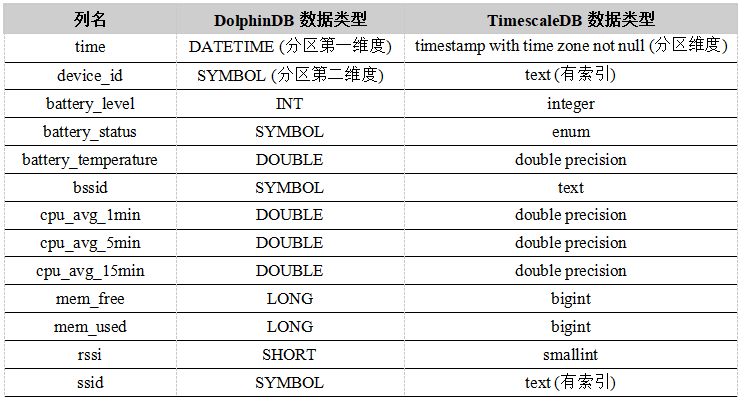
我们在 DolphinDB database 中的分区方案是将time作为分区的第一个维度,按天分为 4 个区,分区边界为[2016.11.15 00:00:00, 2016.11.16 00:00:00, 2016.11.17 00:00:00, 2016.11.18 00:00:00, 2016.11.19 00:00:00];再将device_id作为分区的第二个维度,每天一共分 10 个区,最后每个分区所包含的原始数据大小约为100 MB。
我们尝试了在 TimescaleDB 中将device_id作为分区的第二个维度,但经测试90%查询样例的性能反而不如仅由时间维度进行分区,因此我们选择仅按照时间维度和按天分为4个区,该维度和 DolphinDB 的分区方式相同,而device_id这一维度以官方推荐的建立索引的方式(参考https://docs.timescale.com/v1.0/using-timescaledb/schema-management#indexing)来加快查询速度,如下所示。
create index on readings (device_id, time desc); create index on readings (ssid, time desc);
270 GB 股票交易大数据集(CSV 格式,23 个 CSV,65 亿条)
我们将纽约证券交易所(NYSE)提供的 2007.08.01 - 2007.08.31 一个月的股市 Level 1 报价数据作为大数据集进行测试,数据集包含 8000 多支股票在一个月内的交易时间、股票代码、买入价、卖出价、买入量、卖出量等报价信息。
数据集中共有 65 亿(6,561,693,704)条报价记录,一个 CSV 中保存一个交易日的记录,该月共 23 个交易日,未压缩的 CSV 文件共计 270 GB。 来源:https://www.nyse.com/market-data/historical。
taq 表
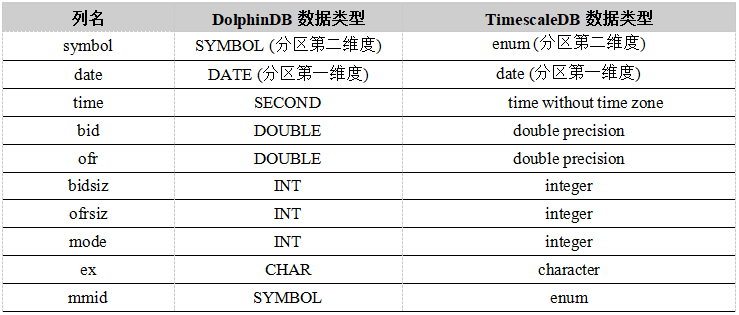
我们按date(日期),symbol(股票代码)进行分区,每天再根据 symbol 分为 100 个分区,每个分区大概 120 MB 左右。
四、数据导入导出测试
从 CSV 文件导入数据
DolphinDB database 使用以下脚本导入:
timer {
for (fp in fps) {
loadTextEx(db, `taq, `date`symbol, fp, ,schema)
print now() + ": 已导入 " + fp
}
}4.2 GB 设备传感器记录小数据集共3千万条数据导入用时 20 秒, 平均速率 1,500,000 条/秒
270 GB 股票交易大数据集共 6,561,693,704 条数据(TAQ20070801 - TAQ20070831 23 个文件),导入用时 38 分钟
在 TimescaleDB 的导入中,由于 timescaledb-parallel-copy 工具不支持 CSV 首行为列名称,我们先用 tail -n +2 跳过 CSV 首行,再将文件流写入其标准输入。
for f in /data/TAQ/csv/*.csv ; do
tail -n +2 $f | timescaledb-parallel-copy \
--workers 12 \
--reporting-period 1s \
--copy-options "CSV" \
--connection "host=localhost user=postgres password=postgres dbname=test sslmode=disable" \
--db-name test \
--table taq \
--batch-size 200000
echo "文件 $f 导入完成"
done4.2 GB 设备传感器记录小数据集共3千万条数据导入用时 5 分钟 45 秒, 平均速率 87,000 条/秒
270 GB 股票交易大数据集仅 TAQ20070801, TAQ20070802, TAQ20070803, TAQ20070806, TAQ20070807 五个文件(总大小 70 GB)所包含的 16.7 亿 条数据导入用时 24 小时,导入速率 19400 条/秒,预计将数据全部 270 GB 数据导入需要 92 小时。
导入性能如下表所示:
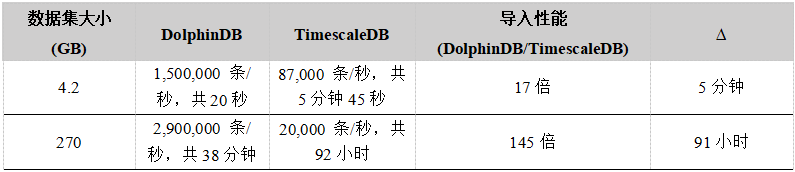
结果显示, DolphinDB 的导入速率远大于 TimescaleDB 的导入速率,数据量大时差距更加明显,而且在导入过程中可以观察到随着导入时间的增加,TimescaleDB 的导入速率不断下降,而 DolphinDB 保持稳定。
另,TimescaleDB 在导入小数据集后仍需花费 2 min 左右的时间建立索引。
导出数据为 CSV 文件
在 DolphinDB 中使用 saveText((select * from readings), '/data/devices/readings_dump.csv') 进行数据导出。
在 TimescaleDB 中使用 time psql -d test -c "\COPY (SELECT * FROM readings) TO /data/devices/devices_dump.csv DELIMITER ',' CSV" 进行数据导出。
小数据集的导出性能如下表所示:

五、磁盘空间占用对比
导入数据后对 TimescaleDB 和 DolphinDB 数据库占用空间的分析如下表所示:

DolphinDB 的空间利用率远大于 TimescaleDB,而且 TimescaleDB 中数据库占用的存储空间甚至大于原始 CSV 数据文件的大小,这主要有以下几方面的原因:
- Timescale 只对比较大的字段进行自动压缩(TOAST),对数据表没有自动压缩的功能,即如果字段较小、每行较短而行数较多,则数据表不会进行自动压缩,若使用 ZFS 等压缩文件系统,则会显著影响查询性能;而 DolphinDB 默认采用 LZ4 格式的压缩。
- TimescaleDB 使用 SELECT create_hypertable('readings', 'time', chunk_time_interval => interval '1 day') 将原始数据表转化为 hypertable 抽象表来为不同的数据分区提供统一的查询、操作接口,其底层使用 hyperchunk 来存储数据,经分析发现 hyperchunk 中对时序数据字段的索引共计 0.8 GB,对 device_id, ssid 两个字段建立的索引共计 2.3 GB。
- device_id, ssid, bssid 字段有大量的重复值,但 bssid 和 ssid 这两个字段表示设备连接的 WiFi 信息,在实际中因为数据的不确定性,因此不适合使用 enum 类型,只能以重复字符串的形式存储;而 DolphinDB 的 Symbol 类型可以根据实际数据动态适配,简单高效地解决了存储空间的问题。
六、查询测试
我们一共对比了以下八种类别的查询:
- 点查询指定某一字段取值进行查询
- 范围查询针对单个或多个字段根据时间区间查询数据
- 精度查询针对不同的标签维度列进行数据聚合,实现高维或者低维的字段范围查询功能
- 聚合查询是指时序数据库有提供针对字段进行计数、平均值、求和、最大值、最小值、滑动平均值、标准差、归一等聚合类 API 支持
- 对比查询按照两个维度将表中某字段的内容重新整理为一张表格(第一个维度作为列,第二个维度作为行)
- 抽样查询指的是数据库提供数据采样的 API,可以为每一次查询手动指定采样方式进行数据的稀疏处理,防止查询时间范围太大数据量过载的问题
- 关联查询对不同的字段,在进行相同精度、相同的时间范围进行过滤查询的基础上,筛选出有关联关系的字段并进行分组
- 经典查询是实际业务中常用的查询
4.2 GB 设备传感器记录小数据集查询测试
对于小数据集的测试,我们先将数据表全部加载至内存中。
DolphinDB 使用 loadTable(memoryMode=true) 加载至内存。
TimescaleDB 使用 select pg_prewarm('_hyper_2_41_chunk') 加载至 shared_buffers。
查询性能如下表所示。查询脚本见附录。
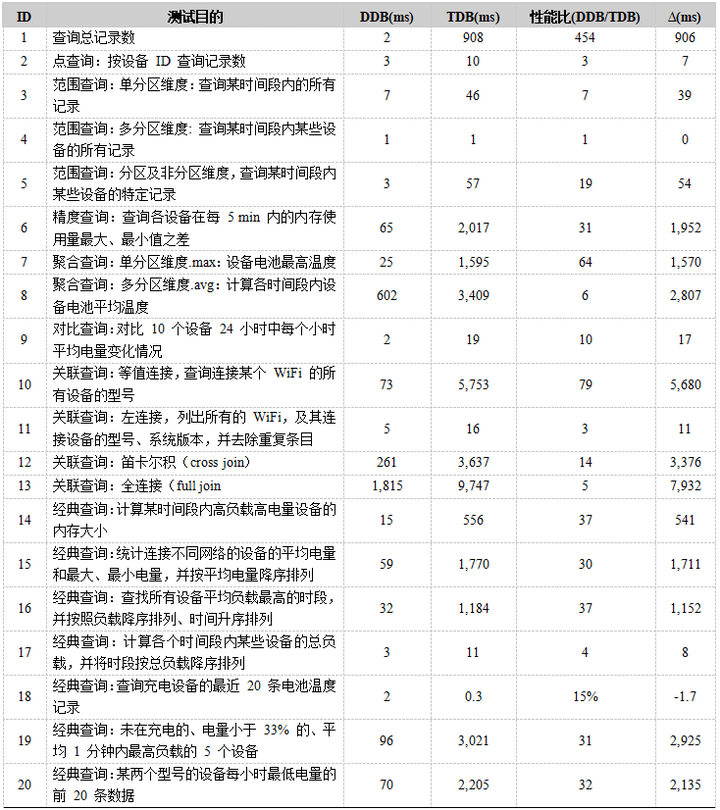
对于抽样查询,TimescaleDB 中有 tablesample 子句对数据表进行抽样,参数是采样的比例,但只有两种抽样方式(system, bernoulli),system 方式按数据块进行取样,性能较好,但采样选中的块内的所有行都会被选中,随机性较差。bernoulli 对全表进行取样,但速度较慢。这两种取样方式不支持按某一个字段进行取样;而 DolphinDB 不支持全表取样,只支持按分区取样,由于实现方式不同,我们不进行性能对比。
对于插值查询,TimescaleDB (PostgreSQL) 无内置插值查询支持,需要上百行代码来实现,见 https://wiki.postgresql.org/wiki/Linear_Interpolation ;而 DolphinDB 支持 4 种插值方式,ffill 向后取非空值填充、bfill 向前去非空值填充、lfill 线性插值、nullFill 指定值填充。
对于对比查询,TimescaleDB 的对比查询功能由 PostgresQL 内置的 tablefunc 插件所提供的 crosstab() 函数实现,但是从样例查询中可以看出该函数有很大的局限性:
第一,它需要用户手动硬编码第二个维度(行)中所有可能的取值和对应的数据类型,无法根据数据动态生成,非常繁琐,因此不能对动态数据或取值多的字段使用。
第二,它只能根据 text 的类型维度进行整理,或者由其它类型的维度事先转换为 text 类型。数据量大时该转换操作效率低下且浪费空间。
而 DolphinDB 原生支持 pivot by 语句,只需指定分类的两个维度即可自动整理。
对于关联查询,双时间连接(asof join)对于时间序列数据分析非常方便。DolphinDB 原生支持 asof join 而 PostgresQL 暂不支持 https://github.com/timescale/timescaledb/issues/271。
使用 count(*) 查询总记录数时,TimescaleDB 会对全表进行扫描,效率极低。
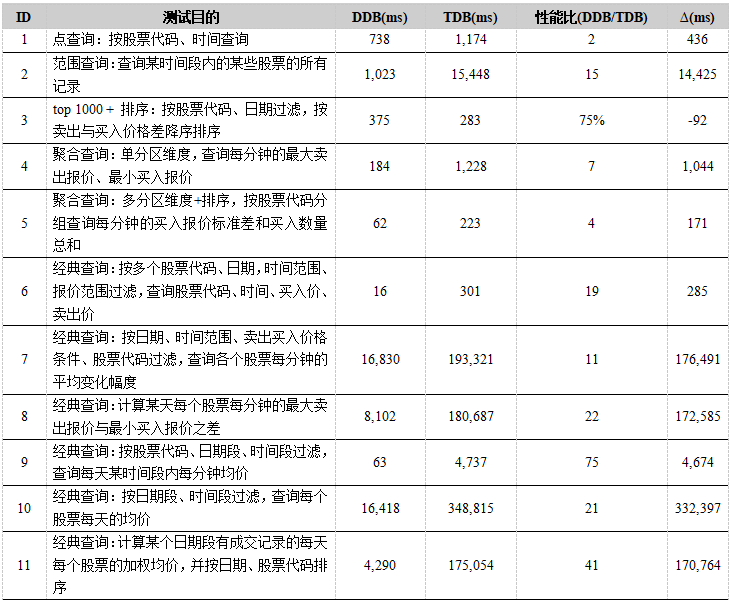
270 GB 股票交易大数据集查询测试
在大数据量级的测试中我们不预先加载硬盘分区表至内存,查询测试的时间包含磁盘 I/O 的时间,为保证测试公平,每次启动程序测试前均通过 Linux 系统命令sync; echo 1,2,3 | tee /proc/sys/vm/drop_caches清除系统的页面缓存、目录项缓存和硬盘缓存,启动程序后依次执行所有测试样例一遍。
查询性能如下表所示。查询脚本见附录。
七、附录
- CSV 数据格式预览(取前 20 行)
device_info:devices.csv
readings:readings.csv
TAQ:TAQ.csv
- DolphinDB
安装、配置、启动脚本:test_dolphindb.sh
配置文件:dolphindb.cfg
小数据集测试完整脚本:test_dolphindb_small.txt
大数据集测试完整脚本:test_dolphindb_big.txt
- TimescaleDB
安装、配置、启动脚本:test_timescaledb.sh
小数据集测试完整脚本:test_timescaledb_small.sql
大数据集测试完整脚本:test_timescaledb_big.sql
PostgreSQL修改配置:postgresql_test.conf
PostgreSQL完整配置:postgresql.conf
PostgreSQL权限配置:pg_hba.conf
股票代码的所有可能值:symbols.txt
创建Symbol枚举类型的SQL语句:make_symbol_enum.sql
生成Symbol枚举类型的脚本:make_symbol_enum.coffee
- 测试结果处理脚本
- 发表于 2021-08-05 17:23
- 阅读 ( 3805 )
- 分类:DolphinDB和大数据
