DolphinDB插件开发教程
DolphinDB支持动态加载外部插件,以扩展系统功能。插件用C++编写,需要编译成".so"或".dll"共享库文件。本文着重介绍开发插件的方法和注意事项,并详细介绍以下几个具体场景的插件开发流程:...
- 0
- 293
- Junxi
- 发布于 2021-08-05 17:26
- 阅读 ( 5683 )
DolphinDB作业管理概述
作业(Job)是DolphinDB中最基本的执行单位,可以简单理解为一段DolphinDB脚本代码在DolphinDB系统中的一次执行。Job根据阻塞与否可分成同步作业和异步作业。 同步作业 同步作业也称为交互式...
- 0
- 0
- Junxi
- 发布于 2021-08-05 17:25
- 阅读 ( 3745 )
DolphinDB与MongoDB在时序数据上的对比测试
DolphinDB和MongoDB都是为大数据而生的数据库。但是两者有这较大的区别。前者是列式存储的多模型数据库,主要用于结构化时序数据的高速存储、查询和分析。后者是文档型的NoSQL数据库,可用于处...
- 0
- 1
- Junxi
- 发布于 2021-08-05 17:24
- 阅读 ( 3908 )
时序数据库DolphinDB和TimescaleDB 性能对比测试报告
一、概述 DolphinDB DolphinDB 是以 C++ 编写的一款分析型的高性能分布式时序数据库,使用高吞吐低延迟的列式内存引擎,集成了功能强大的编程语言和高容量高速度的流数据分析系统,可在数据库...
- 0
- 0
- Junxi
- 发布于 2021-08-05 17:23
- 阅读 ( 3801 )
DolphinDB与Aliyun HybridDB for PostgreSQL在金融数据集上的比较
1. 概述 DolphinDB 是一款高性能混合列式数据库和数据分析系统,尤其擅长处理时间序列数据。Aliyun HybridDB for PostgreSQL(以下简称HybridDB)是由阿里巴巴提供的基于开源Greenplum定制的MP...
- 0
- 294
- Junxi
- 发布于 2021-08-05 17:21
- 阅读 ( 5548 )
时序数据库DolphinDB与Druid的对比测试
DolphinDB和Druid都是分布式的分析型时序数据库。尽管前者使用c++开发,后者使用java开发,两者在架构、功能、应用场景等方面有很多共同点。本报告在SQL查询、数据导入、磁盘占用空间等方面对两...
- 0
- 0
- Junxi
- 发布于 2021-08-05 17:21
- 阅读 ( 3560 )
DolphinDB与Elasticserach在金融数据集上的性能对比测试
Elasticsearch是一款非常流行的日志检索和分析工具,尤其在实时性、扩展性、易用性和全文检索方面有着非常优异的综合表现。知乎上有一篇文章,Golion:降维打击!使用ElasticSearch作为时序数据...
- 0
- 0
- Junxi
- 发布于 2021-08-05 17:20
- 阅读 ( 3569 )
高速迁移MySQL数据到分布式时序数据库DolphinDB
DolphinDB提供了两种导入MySQL数据的方法:ODBC插件和MySQL插件。我们推荐使用MySQL插件导入MySQL数据,因为它的速度比ODBC导入更快,导入6.5G数据,MySQL插件的速度是ODBC插件的4倍,并且使用M...
- 0
- 293
- Junxi
- 发布于 2021-08-05 17:19
- 阅读 ( 5808 )

随机森林算法实现的性能对比测试
随机森林是常用的机器学习算法,既可以用于分类问题,也可用于回归问题。本文对scikit-learn、Spark MLlib、DolphinDB、xgboost四个平台的随机森林算法实现进行对比测试。评价指标包括内存占用...
- 0
- 2
- Junxi
- 发布于 2021-08-05 17:17
- 阅读 ( 3898 )
如何水平扩展和垂直扩展DolphinDB集群?
随着业务的扩展,数据量不断积累,数据库系统的数据容量和计算能力会逐渐不堪重负,因此优秀的数据库系统必须具备良好的扩展性。DolphinDB集群中的数据节点是集计算和存储于一体的,所以要提高...
- 1
- 1
- Junxi
- 发布于 2021-08-05 17:16
- 阅读 ( 3700 )
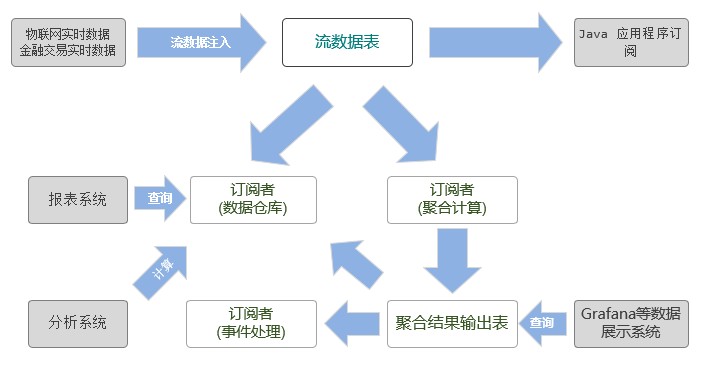
DolphinDB流数据教程
实时流处理一般是将业务系统产生的数据进行实时收集,交由流处理框架进行数据清洗,统计,入库,并可以通过可视化的方式对统计结果进行实时的展示。传统的面向静态数据表的计算引擎无法胜任流数...
- 0
- 2
- Junxi
- 发布于 2021-08-05 17:15
- 阅读 ( 4168 )

DolphinDB流数据聚合引擎教程
流数据是指随时间持续增长的动态数据。互联网的运营数据和物联网的传感器数据都属于流数据的范畴。流数据的特性决定了它的数据集是动态变化的,传统的面向静态数据表的计算引擎无法胜任流数据领...
- 0
- 0
- Junxi
- 发布于 2021-08-05 17:13
- 阅读 ( 3939 )
DolphinDB分区数据库教程(二)
DolphinDB分区数据库教程(一)介绍了DolphinDB的几种分区方式,本文将会详细讲解DolphinDB的分区原则、特殊的分区方案,让用户对DolphinDB分区数据库有更深入的了解。 1.分区原则 分区的总原...
- 1
- 1
- Junxi
- 发布于 2021-08-05 17:12
- 阅读 ( 3993 )
DolphinDB分区数据库教程(一)
1.为什么对数据进行分区? 对数据库进行分区可以极大的降低系统响应延迟同时提高数据吞吐量。具体来说,分区有以下几个好处: 分区使得大型表更易于管理。对数据子集的维护操作也更加高效,因...
- 1
- 0
- Junxi
- 发布于 2021-08-05 17:11
- 阅读 ( 3983 )

DolphinDB数据导入教程
企业在使用大数据分析平台时,首先需要把海量数据从多个数据源迁移到大数据平台中。 在导入数据前,我们需要理解 DolphinDB database 的基本概念和特点。 DolphinDB数据表按存储介质分为3种...
- 1
- 0
- Junxi
- 发布于 2021-08-05 17:10
- 阅读 ( 3854 )

国内股票行情数据导入实例
DolphinDB提供了详细的文本数据加载教程,以帮助用户导入数据。本文是以此为基础的一个实践案例,对每只股票每天一个csv文件的导入场景,提供了一个高性能的解决方案。 1. 应用需求2. 建库建表...
- 1
- 1
- Junxi
- 发布于 2021-08-05 17:06
- 阅读 ( 4522 )
大数据分析语言DolphinDB脚本语言概述
开发大数据应用,不仅需要能支撑海量数据的分布式数据库,能高效利用多核多节点的分布式计算框架,更需要一门能与分布式数据库和分布式计算有机融合、高性能易扩展、表达能力强、满足快速开发和...
- 1
- 0
- Junxi
- 发布于 2021-05-20 12:14
- 阅读 ( 3949 )

DolphinDB VS kdb+的个人测评
kdb+是一款性能极佳的时间序列数据库。它是美国华尔街各大金融机构20多年来处理大规模数据的首选系统。它通常用于高频交易,非常适用于高速存储、分析、处理和检索大型数据集。在存取和实时分析...
- 0
- 0
- Junxi
- 发布于 2021-05-20 12:11
- 阅读 ( 4301 )

DolphinDB与Pandas对于大文本文件处理的性能对比
DolphinDB是一款高性能的分布式时序数据库。它集成了功能强大的编程语言和高容量高速度的流数据分析系统,为海量数据(特别是时间序列数据)的快速存储、检索、分析及计算提供一站式解决方案。...
- 0
- 0
- Junxi
- 发布于 2021-05-20 12:09
- 阅读 ( 4012 )
揭秘高性能DolphinDB
DolphinDB是由浙江智臾科技有限公司自主研发,于2018年初发布的高性能的磁盘与内存混合型和列式分布式数据库产品。DolphinDB集成了功能强大的编程语言和高容量高速度的流数据分析系统,为海量数...
- 0
- 0
- Junxi
- 发布于 2021-05-20 12:04
- 阅读 ( 3984 )