5 如何去重复,如何筛选重复数据,数据库去重案例,去除重复数据案例,键值唯一,键值案例
最佳答案 2021-11-15 15:35
在写入数据时,就可以对数据进行去重。此功能要在2.0及以上版本支持,使用version()函数可以查看版本,如果版本过低,请在官网上下载更新版本。
去重功能要使用TSDB引擎,即,database函数中参数engine指定为TSDB,代码如下:
login(`admin,`123456)
if(existsDatabase("dfs://tsdb"))
{
dropDatabase("dfs://tsdb")
}
//创建分区数据库,engine参数指定为TSDB
db_tsdb = database(directory = "dfs://tsdb", partitionType = VALUE, partitionScheme = 2012.03.01..2022.12.31, engine = 'TSDB')
创建数据库完成后,再创建三个分布式表。建表时,通过sortColumns参数指定键值,通过keepDuplicates参数指定数据的去重规则。
- LAST:保存最新数据。
- ALL:保存所有数据。
- FIRST:保存第一条数据。
在本例中,键值列是Date和ID,建立三个分布式表,last,all,first,其去重规则分别是LAST,ALL和FIRST,代码如下
//创建分区表时提供表结构
t = table(1:0,`Date`ID`Close,[DATETIME,SYMBOL,DOUBLE])
//创建分区表,用ID和Date作为键值,保留最新的值
tsdb_table = createPartitionedTable(dbHandle = db_tsdb, table=t, tableName="last", sortColumns=["ID","Date"], partitionColumns=`Date, keepDuplicates=LAST)
last = db_tsdb.loadTable(`last)
//创建分区表,用ID和Date作为键值,保留所有值
tsdb_table = createPartitionedTable(dbHandle = db_tsdb, table=t, tableName="all", sortColumns=["ID","Date"], partitionColumns=`Date, keepDuplicates=ALL)
all = db_tsdb.loadTable(`all)
//创建分区表,用ID和Date作为键值,保留第一个值
tsdb_table = createPartitionedTable(dbHandle = db_tsdb, table=t, tableName="first", sortColumns=["ID","Date"], partitionColumns=`Date, keepDuplicates=FIRST)
first = db_tsdb.loadTable(`first)
我们构造数据进行第一次写入,并查看结结果。代码如下
//构造第一次写入的数据
Date = 2012.03.01 09:30:00..(2012.03.01 09:30:00 + 4)
ID = `000001`000001`000002`000002`000002
Close =1.0 2.0 3.0 4.0 5.0
first_table = table(Date,ID,Close)
//第一次写入数据
last.append!(first_table)
all.append!(first_table)
first.append!(first_table)
//第一次查询数据,三个表的结果都是一样的
select * from last
select * from all
select * from first
执行select后,三个表的结果都是一样的,内容如下:
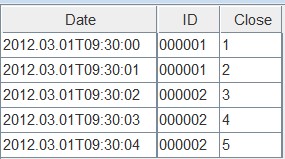 接下来我们再次写入数据,注意,这次的Date、ID和上次的写入是一样的,Close是不一样的,注意观察三个表在同样的键值下,不同去重规则时,Close的值的变
接下来我们再次写入数据,注意,这次的Date、ID和上次的写入是一样的,Close是不一样的,注意观察三个表在同样的键值下,不同去重规则时,Close的值的变
//构造第二次写入的数据
Date = 2012.03.01 09:30:00..(2012.03.01 09:30:00 + 4)
ID = `000001`000001`000002`000002`000002
Close =10.0 20.0 30.0 40.0 50.0
second_table = table(Date,ID,Close)
//第二次写入数据
last.append!(second_table)
all.append!(second_table)
first.append!(second_table)
//第二次查询数据,可以发现last表中Close的值变成了第二次写入的数据,all表中两次写入的数据都有,first表中还是第一次写入的数据
select * from last
select * from all
select * from first
这次的三个查询,三个表根据不同的去重规则,有了不同的数据,last表参数值是LAST,它保存了第二次写入的数据内容,如下图:
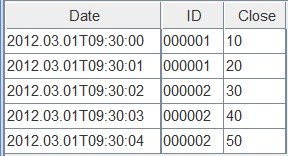 first表的参数是FIRST,它保留了第一次写入的数据内容,如下图:
first表的参数是FIRST,它保留了第一次写入的数据内容,如下图:
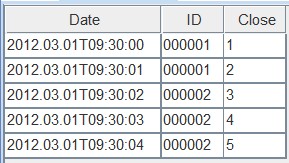
all表的参数值是ALL,它把两次写入的内容都保留了,如下图:
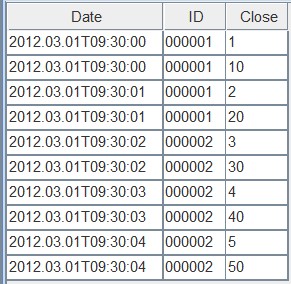 案例的完整脚本如下:
案例的完整脚本如下:
login(`admin,`123456)
if(existsDatabase("dfs://tsdb"))
{
dropDatabase("dfs://tsdb")
}
//创建分区数据库,engine参数指定为TSDB
db_tsdb = database(directory = "dfs://tsdb", partitionType = VALUE, partitionScheme = 2012.03.01..2022.12.31, engine = 'TSDB')
//创建分区表时提供表结构
t = table(1:0,`Date`ID`Close,[DATETIME,SYMBOL,DOUBLE])
//创建分区表,用ID和Date作为键值,保留最新的值
tsdb_table = createPartitionedTable(dbHandle = db_tsdb, table=t, tableName="last", sortColumns=["ID","Date"], partitionColumns=`Date, keepDuplicates=LAST)
last = db_tsdb.loadTable(`last)
//创建分区表,用ID和Date作为键值,保留所有值
tsdb_table = createPartitionedTable(dbHandle = db_tsdb, table=t, tableName="all", sortColumns=["ID","Date"], partitionColumns=`Date, keepDuplicates=ALL)
all = db_tsdb.loadTable(`all)
//创建分区表,用ID和Date作为键值,保留第一个值
tsdb_table = createPartitionedTable(dbHandle = db_tsdb, table=t, tableName="first", sortColumns=["ID","Date"], partitionColumns=`Date, keepDuplicates=FIRST)
first = db_tsdb.loadTable(`first)
//构造第一次写入的数据
Date = 2012.03.01 09:30:00..(2012.03.01 09:30:00 + 4)
ID = `000001`000001`000002`000002`000002
Close =1.0 2.0 3.0 4.0 5.0
first_table = table(Date,ID,Close)
//第一次写入数据
last.append!(first_table)
all.append!(first_table)
first.append!(first_table)
//第一次查询数据,三个表的结果都是一样的
select * from last
select * from all
select * from first
//构造第二次写入的数据
Date = 2012.03.01 09:30:00..(2012.03.01 09:30:00 + 4)
ID = `000001`000001`000002`000002`000002
Close =10.0 20.0 30.0 40.0 50.0
second_table = table(Date,ID,Close)
//第二次写入数据
last.append!(second_table)
all.append!(second_table)
first.append!(second_table)
//第二次查询数据,可以发现last表中Close的值变成了第二次写入的数据,all表中两次写入的数据都有,first表中还是第一次写入的数据
select * from last
select * from all
select * from first