可以给出更详细信息吗
2 个回答
第一种情况
也是最为常见的,建表时使用RANGE分区,写入数据时,分区字段不在RANGE范围内,举例如下:
login(`admin, `123456)
db = database("dfs://test", RANGE, 0 10 20 30)
model = table(1:0, `ID`Sym`Date`Value, [INT, SYMBOL, DATE, FLOAT])
createPartitionedTable(db, model, "test", `ID)
test_dfs = loadTable("dfs://test", "test")
// 第一次写入
t = table(20 as ID, `A as Sym, 2022.04.30 as Date, 1.0 as Value)
test_dfs.append!(t)
select * from test_dfs // 可以查到ID=20的数据
// 第二次写入
t = table(40 as ID, `A as Sym, 2022.04.30 as Date, 1.0 as Value)
test_dfs.append!(t)
select * from test_dfs // 无法查到ID=40的数据
原因是RANGE分区不会自动扩展,ID=40在分区方案之外,可以使用addRangePartitions 函数增加分区,新的分区必须按照升序排列,并且第一个元素必须与数据库的原分区方案的最后一个元素相同。
addRangePartitions(db, 30 40 50 60 70 80 90, level=0)
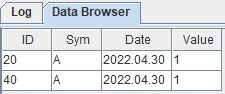
添加新的分区后,再次执行第二次写入,可以查到ID=40的数据,如下图所示:
其次,LIST分区也可能存在类似问题,如下示例
db = database("dfs://listdb", LIST, [`IBM`ORCL`MSFT, `GOOG`FB])
model = table(1:0, `Ticker`Value, [SYMBOL, FLOAT])
createPartitionedTable(db, model, `test, `Ticker)
listdb_dfs = loadTable("dfs://listdb", "test")
// 第一次写入
t = table(`IBM as Ticker, 1.0 as Value)
listdb_dfs.append!(t)
select * from listdb_dfs // 可以查到Ticker=`IBM的数据
// 第二次写入
t = table(`XXX as Ticker, 1.0 as Value)
listdb_dfs.append!(t)
select * from listdb_dfs // 无法查到Ticker=`XXX的数据
所以,对于LIST、RANGE分区,建议规划方案之初就将方案订好,或预留一定弹性,以免出现写入后查不到数据问题。