分布式表建议用context by去重:
select top 1 * from tb_kline context by DT,Code
如果要取最后一条记录,可以用limit -1:
select * from tb_kline context by DT, Code limit -1
我在DolphinDB database中有一张分布式表tb_kline,其字段和数据如下图所示:
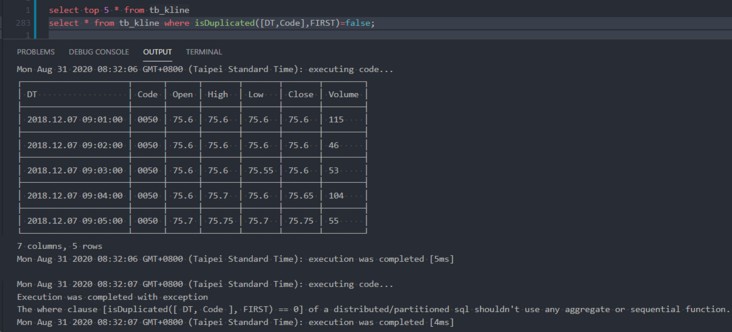 现在我要把tb_kline中DT,Code重复的过滤掉,代码如下:
现在我要把tb_kline中DT,Code重复的过滤掉,代码如下:
select * from tb_kline where isDuplicated([DT,Code],FIRST)=false
但执行时报错如下:
The where clause [isDuplicated([ DT, Code ], FIRST) == 0] of a distributed/partitioned sql shouldn't use any aggregate or sequential function.
我上面那个语法,是哪里写错了吗?
分布式表建议用context by去重:
select top 1 * from tb_kline context by DT,Code
如果要取最后一条记录,可以用limit -1:
select * from tb_kline context by DT, Code limit -1
对于分布式表的去重查询也可以这样写:
select * from tb_kline where isDuplicated([DT, Code], FIRST)=false map