可以通过getTabletsMeta函数获取当前节点上指定数据表chunk的元数据信息,结合pnodeRun函数获取各个数据节点上指定数据表chunk的元数据信息,然后通过条件删选就可以得到上面场景需要的信息:
具体代码如下:
select dfsPath from pnodeRun(getTabletsMeta) where tableName = 'trades' and like(dfsPath, '%20190102%')
返回结果如下:
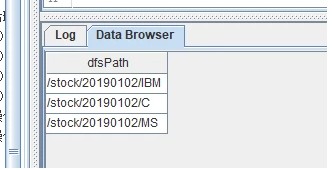
说明涉及了3个分区,分别如图中所示。
可以通过getTabletsMeta函数获取当前节点上指定数据表chunk的元数据信息,结合pnodeRun函数获取各个数据节点上指定数据表chunk的元数据信息,然后通过条件删选就可以得到上面场景需要的信息:
具体代码如下:
select dfsPath from pnodeRun(getTabletsMeta) where tableName = 'trades' and like(dfsPath, '%20190102%')
返回结果如下:
说明涉及了3个分区,分别如图中所示。
可以使用 sqlDS,根据输入的 SQL 元代码创建数据源列表。如果 SQL 查询中的数据表有 n 个分区,sqlDS 生成 n 个数据源。具体代码如下:
sqlDS(<select * from trades where date=2019.01.02>).size()
返回结果为3,与期望一致。
分区分别为:20190102/C、20190102/IBM、20190102/MS