我有一份csv文件想导入dolphindb,原始数据的前两列内容如下,且没有字段名:
 第一个字段名应该是time,类型应该是STRING,且带有单引号('');
第一个字段名应该是time,类型应该是STRING,且带有单引号('');
第二个字段名应该是id,类型应该也是STRING,且带有单引号(''),但是有效id的长度是6位,也有可能是5位,所以用下列代码导入时有问题:
//创建分区数据库和表
def createDatabaseAndTable(dbUrl, tableName){
if(existsDatabase(dbUrl)){
dropDatabase(dbUrl)
}
dbDate = database("", RANGE, date(datetimeAdd(2010.01M,0..15*12,'M')))
dbSymbol = database("", HASH, [SYMBOL, 20])
db = database(dbUrl, COMPO, [dbDate, dbSymbol])
databaseTable = table(1:0, `time`id`price, [TIMESTAMP,SYMBOL,DOUBLE])
return createPartitionedTable(db, databaseTable, tableName, `time`id)
}
//d2m函数:loadTextEx函数的一个参数,读取表的id列时去掉首末的单引号
def d2m(mutable t){
return t.replaceColumn!("id", t.id.substr(1, 6))
}
//向数据库导入数据文件
def loadCsv(filePath, dbHandle, tableName){
schemaTB = extractTextSchema(filePath)
update schemaTB set name=`time`id`price
update schemaTB set type="TIMESTAMP" where name="time"
update schemaTB set type="STRING" where name="id"
schemaTB["format"]=array(STRING, schemaTB.rows()).fill!(0,"'yyyy-MM-dd HH:mm:ss.SSS'")
loadTextEx(dbHandle=dbHandle, tableName=tableName, partitionColumns=`time`id, filename=filePath, schema=schemaTB, transform=d2m)
}
//用loadTextEx函数直接导入数据库
//创建或访问数据库需要权限,初次连接数据节点时,登陆一次即可
login("admin","123456")
filePath ="F:/Data/test.csv"
dbUrl="dfs://testDB"
tableName = "testTable"
//创建数据库和表
createDatabaseAndTable(dbUrl, tableName)
//获取数据库的handle
db=database(dbUrl)
//将csv数据文件导入数据库
loadCsv(filePath, db, tableName)
//查询
tb = loadTable(dbUrl,tableName)
select * from tb
有效id的长度是5位的数据导入进来是这样的:
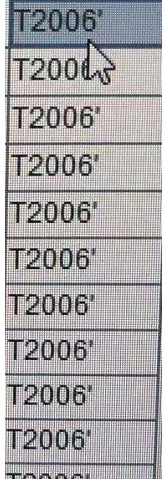
请问应该怎么办?