 如图为id_partition=1的分区,有20,000个id_key,这里需要在往库里写数据时,以id_key为主键,保留最新的数据,最后按时间列排序。
如图为id_partition=1的分区,有20,000个id_key,这里需要在往库里写数据时,以id_key为主键,保留最新的数据,最后按时间列排序。如果使用 TSDB 存储引擎,参数 sortColumns 表示为字符串标量或向量,用于指定表的排序列。系统默认 sortColumns 最后一列为时间列,其余列字段作为排序的索引列,其组合值称作 sortKey。不支持将 sortColumns 设置为不包含时间列,不符合当前场景。这里建议使用 OLAP 存储引擎,并且在写入数据时使用 upsert! 接口,具体操作如下:
dbName = "dfs://test_1123"
tbName = "test_1123"
if(existsDatabase(dbName)){
dropDatabase(dbName)
}
//使用OLAP引擎,按id_partition分区,没有sortColumns
db = database(dbName, VALUE, `client01`client02)
colNames = `DateTime`id_key`id_partition`factor
colTypes = [DATETIME, LONG, SYMBOL, DOUBLE]
schemaTable = table(1:0, colNames, colTypes)
db.createPartitionedTable(table=schemaTable, tableName=tbName, partitionColumns=`id_partition)
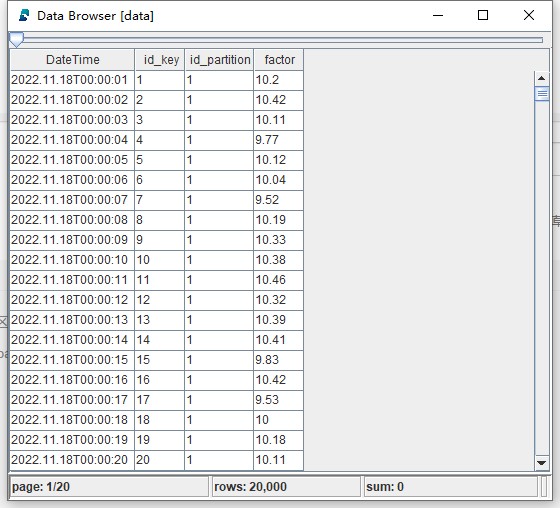
//一个分区的demo数据,id_partition都为1,id_key为1-20000,将其先存入空的分区表中。字段有DateTime、id_key、id_partition、factor
data = table(2022.11.18T00:00:00 + 1..20000 as DateTime, take(1..20000, 20000) as id_key, take(`1, 20000) as id_partition, 10.5 - round(rand(1.0, 20000), 2) as factor)
pt = loadTable(dbName, tbName).upsert!(newData=data, ignoreNull=false, keyColNames=`id_key, sortColumns=`id_partition)
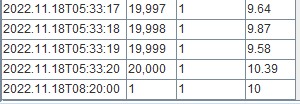
//一条新的输入数据,id_partition为1,id_key为1,DateTime晚于库中的数据的时间。使用upsert!向分区表中插入数据。
inputOne = table(2022.11.18T00:00:00 + 30000 as DateTime, 1 as id_key, `1 as id_partition, 10.0 as factor)
pt.upsert!(newData=inputOne, ignoreNull=false, keyColNames=`id_key, sortColumns=`DateTime)
结果:

另外需要注意的是,upsert! 写入数据的特点是:若新数据的主键值已存在,更新该主键值的数据;否则添加数据。也就是说,如果写入的数据(一个batch)里面存在多条重复的数据,其主键在原来的表里没有时:会把所有的数据都添加进去,没有去重。所以说,在使用 upsert! 写入数据的时候必须要保证每一个 batch 中没有重复的、新的主键的数据。例如:
inputOneDuplicated = table(2022.11.18T00:00:00 + 30000..30001 as DateTime, [20001, 20001] as id_key, `1`1 as id_partition, [10.0, 10.1] as factor) pt.upsert!(newData=inputOneDuplicated, ignoreNull=false, keyColNames=`id_key, sortColumns=`DateTime)