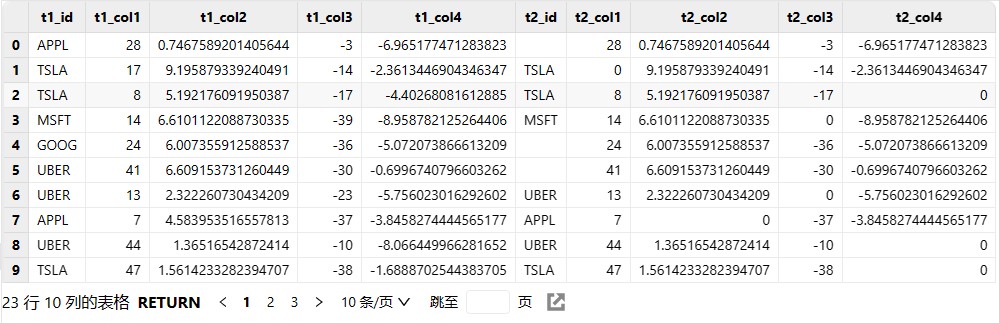
demo如下:
select * from unionAll(t1,t2) where isDuplicated([time,code,val1],NONE)=false
填入相比较的字段,输出结果是两表比较字段有差异的数据的并集
demo如下:
select * from unionAll(t1,t2) where isDuplicated([time,code,val1],NONE)=false
填入相比较的字段,输出结果是两表比较字段有差异的数据的并集
t1 = table(`a`a`b`b`c as sym, 1 2 3 4 5 as val1, 6 7 8 9 10 as val2)
t2 = table(`a`a`b`b`c as sym, 1 2 3 7 5 as val1, 6 7 8 9 10 as val2)
def eqTable(t1, t2): eqObj :E:E (t1, t2)
colList= `val1`val2 // 指定比较的字段
re = eqTable(t1[colList], t2[colList]).rename!(colList)
可以通过上述脚本比较每个值的差异,不同的值会返回 false
可以通过以下的自定义函数实现比较 tb1 和 tb2,并输出有差异的值的要求。
/**
table1: 表1
table2: 表2
compareCols: 要比较的字段名
返回表1、表2中compareCols字段值有差异的数据。
*/
def findDiff(table1, table2, compareCols) {
t1 = table(table1[compareCols]).rename!("t1_" + compareCols)
t2 = table(table2[compareCols]).rename!("t2_" + compareCols)
return join(t1, t2).at(rowAnd(eqObj:E:E(t1.values(), t2.values())) == false)
}
接下来是使用示例。
首先生成行数为10万的 tb1。
n = 100000 id = rand(`APPL`MSFT`GOOG`SAP`UBER`TSLA, n) col1= rand(50, n) col2 = rand(10.0, n) col3 = -rand(50, n) col4 = -rand(10.0, n) // 创建 tb1 tb1 = table(id, col1, col2, col3, col4)
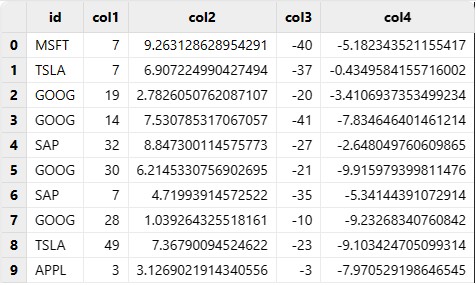
将 tb1 中的每一列随机选5个位置,将值置为0或空字符串,得到 tb2。
id[rand(n, 5)-1] = string(NULL) col1[rand(n, 5)-1] = 0 col2[rand(n, 5)-1] = 0 col3[rand(n, 5)-1] = 0 col4[rand(n, 5)-1] = 0 tb2 = table(id, col1, col2, col3, col4)
例1:比较 id 列
findDiff(tb1,tb2, `id)
 例2:比较表中所有字段,可以如下把字段名一一列出
例2:比较表中所有字段,可以如下把字段名一一列出
findDiff(tb1,tb2, [`id, `col1, `col2, `col3, `col4])
或者使用内置函数 columnNames 获取所有字段名
findDiff(tb1,tb2, tb1.columnNames())