假设有两个 100000 行 100 列的矩阵
setRandomSeed(9) m1 = rand(50.0, 10000000)$100000:100 m2 = rand(1..10, 10000000)$100000:100
需要逐行进行以下计算,最后返回一个 100000 行 100 列的矩阵
def foo(m1Row, m2Row):contextby(demean, m1Row, m2Row)
可以通过以下三种方式实现:
方案一:byRow + 矩阵拼接
byRow 可以对矩阵逐行计算,但是只能传入一个矩阵。所以可以考虑把两个矩阵横向拼接形成一个矩阵,在计算函数里,通过索引的方式把每行数据分成两部分。
res = byRow(def(row):foo(row[0:(size(row)/2)], row[(size(row)/2):])<-take(00F, (size(row)/2)), matrix(m1, m2))[0:cols(m1)]
方案二:each + row(index)
对矩阵使用 each 函数时,默认按列计算。所以可以考虑,按照行号循环,根据 matrix.row(index) 按行取数据。
def foo1(m1, m2, i):foo(m1.row(i), m2.row(i))
res = each(foo1{m1, m2}, til(m1.rows())).transpose()
方案三:each + 转置
对矩阵使用 each 函数时,默认按列计算。所以可以考虑,先用 transpose 函数将矩阵转置后再进行计算。
res = each(foo, m1.transpose(), m2.transpose()).transpose()
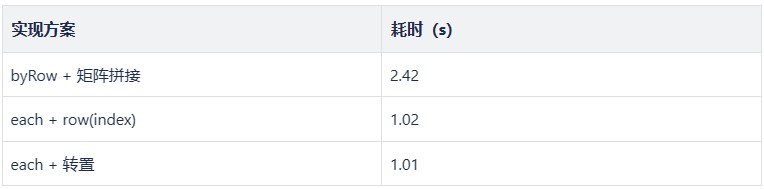
性能测试
数据量:两个矩阵,每个 10 W 行 100 列
测试方案:通过 timer 函数统计单次计算的耗时