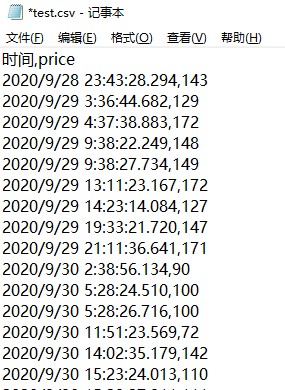
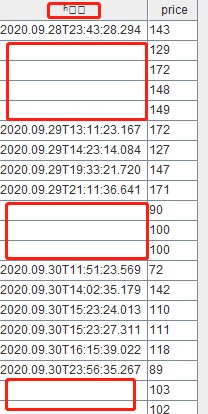
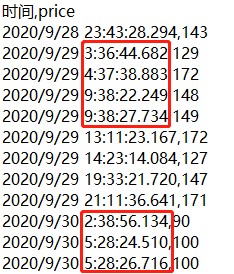
 表示小时的数据没有补全。
表示小时的数据没有补全。1.由于DolphinDB的字符串采用UTF-8编码,若加载的文件不是UTF-8编码,需在导入后进行转化。DolphinDB提供了convertEncode、fromUTF8和toUTF8函数,用于导入数据后对字符串编码进行转换。
例如,使用convertEncode函数转换表tmpTB中的exchange列的编码:
filePath ="F:/Data/test.csv" schemaTB = extractTextSchema(filePath) update schemaTB set name=convertEncode(name,"gbk","utf-8")
2.对于日期列或时间列的数据,如果自动识别的数据类型不符合预期,不仅需要在schema的type列指定数据类型,还需要在format列中指定格式(用字符串表示),如"MM/dd/yyyy"。如何表示日期和时间格式请参考日期和时间的调整及格式。
上述的实际场景可以这么转换:
schemaTB["format"]=["yyyy/MM/dd HH:mm:ss.SSS",]
所以,上述的csv数据文件用ploadText或loadText函数导入内存表可以使用以下代码实现:
filePath ="F:/Data/test.csv" schemaTB = extractTextSchema(filePath) update schemaTB set name=convertEncode(name,"gbk","utf-8") schemaTB["format"]=["yyyy/MM/dd HH:mm:ss.SSS",]//注意["yyyy/MM/dd HH:mm:ss.SSS",]的长度和schemaTB的行数相等 t=ploadText(filePath,,schemaTB)
上述的csv数据文件用loadTextEx函数导入数据库表可以使用以下代码实现:
login("admin","123456") if(existsDatabase("dfs://test")){ dropDatabase("dfs://test") } db=database("dfs://testRongcheng",VALUE,2020.01.01..2021.01.01) filePath = "F:/Data/test.csv" schemaTB = extractTextSchema(filePath) update schemaTB set name=convertEncode(name,"gbk","utf-8") schemaTB["format"]=["yyyy/MM/dd HH:mm:ss.SSS",] loadTextEx(db, "tableTest", "时间", filePath,,schemaTB,) tb = database("dfs://test").loadTable("tableTest")