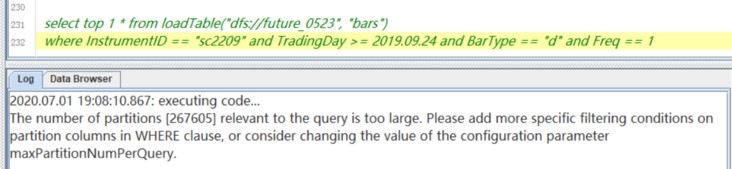

分布式表顾名思义,包含了很多分区。这里虽然只查一条记录,但涉及很多分区。一个query涉及的分区越多,需要耗费资源的越多。maxPartitionNumPerQuery指定一个query最多可以使用多少个分区。默认值是65535。这个分区数目怎么来决定呢?并不是计算实际用到的分区,而是根据datbase中的分区定义信息以及sql语句的where子句中的剪枝信息来决定query涉及到了多少个分区。
本问题中分区字段有两个,TradingDay和ProdutId,query中用到的分区字段就TradingDay,不太清楚数据库定义中TradingDay的范围如何,但如果超过2019.09.24的潜在日期超过1000个,每天65个分区,就有可能超过设定的maxPartitionNumPerQuery
解决这个问题有几个办法:
(1)maxPartitionNumPerQuery 设成很大一个值。但并不推荐这种方法。
(2)定义数据库的分区机制时,TradingDay的定义不要包含将来的日期,可以在系统中将newValuePartitionPolicy设置成add。这样新的日期出现时,系统会自动更新数据库定义。
(3)query中限定日期的范围小一点,譬如TradingDay >= 2019.09.24 and TradingDay <=2019.09.30, ProductId = 'sc'