我用python api导入数据到DolphinDB分布式表,分布式表按月+按股票分区,建库和导入代码如下:
import os
import glob
import pandas as pd
import datetime as dt
import dolphindb as ddb
if __name__ == "__main__":
s = ddb.session()
s.connect(host="10.63.16.165", port=8921, userid="admin", password="123456")
if not s.existsDatabase("dfs://minute_price"):
s.run("valuep = database(, VALUE, date(1990.01M + (0..600)))")
s.run("""tickerp = database(, HASH, [SYMBOL, 20])""")
s.run("""price_data = database("dfs://minute_price", COMPO, [valuep, tickerp])""")
columns = """`code`wind_code`name`date`time`open`high`low`close`volume`turnover`match_items`interest`datetime"""
types = """[SYMBOL,SYMBOL,SYMBOL,DATE,INT,DOUBLE,DOUBLE,DOUBLE,DOUBLE,DOUBLE,DOUBLE,DOUBLE,DOUBLE,TIMESTAMP]"""
s.run("""table_new = price_data.createPartitionedTable(table(10:0, {cols}, {types}), `price_data,
`datetime`code)""".format(cols=columns, types=types))
print("NEW TABLE CREATED....")
# else:
# s.dropDatabase("dfs://minute_price")
DIR = "/mnt/paicdom/Packages/Wind/"
target = "Minute"
start_date = "2015-04-01"
dates = pd.date_range(start_date, "2015-05-01", freq="M")
for date in dates.tolist():
date_str = date.strftime("%Y%m")
dir = DIR + date_str + "/" + date_str + "_" + target
folder_list = os.listdir(dir)
for mk in folder_list:
sub_path = os.path.join(dir, mk)
print("Starting to work on dir: {d}".format(d=sub_path))
sub_dir_list = os.listdir(sub_path)
for sub_dir in sub_dir_list:
sub_sub_dir = os.path.join(sub_path, sub_dir)
file_list = os.listdir(sub_sub_dir)
for file_name in file_list:
file_name = os.path.join(sub_sub_dir, file_name)
data = pd.read_csv(file_name)
time = data.time.astype("str")
cond_sel = ~time.str.startswith("1").copy()
time[cond_sel] = "0" + time[cond_sel]
data["datetime"] = data.date.astype("str") + time.str[0:4]
data["datetime"] = pd.to_datetime(data["datetime"], format="%Y%m%d%H%M")
data["date"] = pd.to_datetime(data["date"], format="%Y%m%d")
data = data.rename(columns={"turover":"turnover", "volumw":"volume"})
data["code"] = data["code"].astype("str")
data["name"] = data["name"].astype("str")
# print(data)
s.upload({"tmp_data": data})
query = """select code,wind_code,name,date(date) as date,time,open,high,low,
close,volume,turnover,match_items,interest,timestamp(datetime) as datetime from tmp_data"""
s.run("tableInsert(loadTable('{db}', `{tb}), ({sel}))".format(db="dfs://minute_price",
tb="price_data",
sel=query))
print("inserted %s" % file_name)
我导入了2015年4月一个月数据,程序写完了,可是查询只能看到2015.04.01的数据,如下图所示,
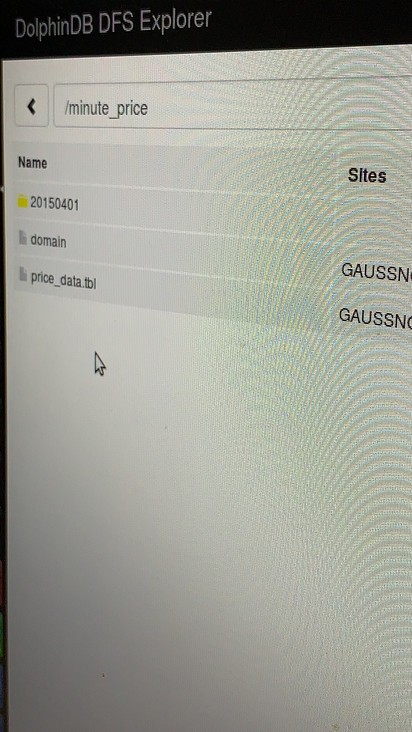
请教各位大佬这是为什么?